
Índice
Overview
Todos sabemos que documentações são importantes. Sem elas, perderíamos o contexto do código ao longo do tempo, mudanças específicas ficariam sem explicação e o conhecimento acumulado simplesmente evaporaria com a rotatividade do time.
O problema é que manter documentação atualizada é difícil. Engenheiros têm deadlines apertadas e documentação raramente entra no definition of done. O resultado é o de sempre: um Notion cheio de páginas desatualizadas que ninguém confia mais.
Com o advento das IAs, podemos reduzir esse problema ao preço de alguns tokens. Fui inspirado em como isso foi feito internamente na empresa em que trabalho e esse artigo discute as estratégias que funcionaram na prática: ADRs, documentação viva integrada ao CI/CD, e como configurar agentes de AI para manter tudo isso funcionando.
ADRs Encadeados
O que é um ADR
Um ADR (Architectural Decision Record) é um documento criado quando se toma uma decisão importante de arquitetura. Ele registra o contexto da discussão, os prós e contras avaliados e o motivo pelo qual aquela decisão foi necessária.
Exemplos de decisões que geram ADRs:
- Qual linguagem de programação ou framework adotar
- Qual banco de dados usar e por quê
- Como lidar com picos de requisição
- Estratégia de autenticação e autorização
Exemplos de ADRs e outros detalhes podem ser explorados no seguinte repositório público.
O problema com ADRs tradicionais
O que normalmente acontece na vida real é: ADRs são criados, ficam em um Notion ou repositório e muitas vezes não são revisitados. Nenhum engenheiro consegue lembrar o contexto inteiro de todos os ADRs de uma empresa e muito menos de ADRs escritos há anos por pessoas que já não trabalham na empresa.
O resultado é inconsistência. Por exemplo: Uma decisão de usar MariaDB com banco de dados foi tomada por um motivo que ninguém mais lembra e uma nova decisão sobre banco de dados ignora completamente o raciocínio anterior.
ADRs encadeados com AI
Aqui começo a explorar uma solução que utiliza agentes de AI para o problema destacado: criar um repositório Git centralizado para todos os ADRs em que cada ADR é feito em cima do anterior, sem paralelismos.
O fluxo é:
- Cria-se uma branch para escrever o novo ADR
- O time revisa e dá merge
- Só então o próximo ADR pode ser criado
ADR-0001 aceito │ ▼Cria branch para ADR-0002 │ ▼ Time revisa ◀──────────────┐ │ │ ▼ │ Aprovado? ──Não──▶ Revisão e correção │ Sim │ ▼Merge do ADR-0002 │ ▼Cria branch para ADR-0003 │ ▼ ...Dessa forma, o histórico de ADRs é uma linha do tempo linear e sequencial. Um ADR é feito após o anterior ter sido aceito. Ou seja, o ADR-0002 precisa da existência de um ADR-0001. Dessa forma os agentes de IA poderão ter acesso a uma linha temporal e todo o contexto organizado de uma codebase.
Com todo esse contexto, podemos perguntar aos agentes, por exemplo:
- Algum ADR explica por que mudamos X feature?
- Qual o contexto anterior para se tomar a decisão do ADR-0052?
- O meu novo ADR criado hoje tem incosistências com algum já feito?
O pipeline de 3 agentes
Para automatizar a criação de novos ADRs, separamos o workflow em 3 sub-agentes:
create-adr-base— O sub-agente cria a base do novo ADR iterando decisões com o engenheiro responsável se utilizado de perguntas pertinentes ao problema que se quer resolver.get-context— O sub-agente lê todos os ADRs anteriores linearmente para montar o contexto do agente principalreview-adr— O sub-agente revisa o ADR criado buscando inconsistências com os anteriores baseado no contexto.
Exemplo de prompts (extremamente simples pois não quero escrever um texto de 100 linhas para cada um):
create-adr-base:
Você é um assistente especializado em criar ADRs (Architectural Decision Records).
1. Pergunte ao engenheiro qual decisão de arquitetura precisa ser registrada.2. Faça perguntas iterativas para entender: o problema, as alternativas consideradas, os trade-offs e a decisão final.3. Gere o ADR no formato padrão (Título, Status, Contexto, Decisão, Consequências) seguindo a numeração sequencial do repositório.4. Salve o arquivo como ADR-XXXX.md na branch correspondente.get-context:
Você é um sub-agente de contexto para ADRs.
1. Leia todos os arquivos ADR-*.md do repositório em ordem numérica crescente.2. Para cada ADR, extraia: número, título, status, decisão principal e consequências.3. Retorne um resumo estruturado de todos os ADRs para servir de contexto ao agente de review. Priorize informações sobre decisões ativas (não superseded).review-adr:
Você é um revisor de ADRs. Você receberá:- O novo ADR a ser revisado- O contexto de todos os ADRs anteriores (fornecido pelo sub-agente get-context)
Sua tarefa:1. Verifique se o novo ADR contradiz decisões anteriores ainda ativas.2. Identifique se algum ADR anterior deveria ter seu status atualizado para "superseded" com base nesta nova decisão.3. Aponte inconsistências de terminologia, padrões ou convenções.4. Retorne um relatório de review com: aprovado/reprovado e lista de observações.O problema do contexto
Se você leu até aqui, deve ter se perguntado: Isto é escalável? A resposta é: Não
Por exemplo, se você tem 200 ADRs, vai gastar muitos tokens para passar ler todos eles com um sub-agente ou vai ultrapassar o context window de um modelo. Cabe ao time entender se o custo vale o benefício. Além disso, existem algumas estratégias para reduzir o contexto como:
- Limite de ADRs recentes: processar apenas os últimos X ADRs (utilizado o sub agente get-context), assumindo que os mais antigos já foram incorporados e não são importantes para tomada de decisão recente.
- Separação por domínio: criar domínios (infra, dados, produto), reduzindo o volume por contexto necessário para um ADR com um domínio específico. Por exemplo: Ao se criar um ADR sobre tabelas em um banco e dados, pode-se usar o sub agente **get-context apenas para carregar oustro documentos que tangem banco de dados
- Arquivo de resumo: manter um
SUMMARY.mdcom apenas algumas linhas explicado o conteúdo de todos os ADR. O agente lê o resumo primeiro e só busca o ADR completo quando necessário
Documentação Viva
Além dos ADRs, existe o problema de atualizar a documentação do dia a dia: READMEs, guias de setup, diagramas de arquitetura. Esses documentos ficam desatualizados rapidamente se não houver um esforço para sempre manter atualizado.
Atualmente pode-se reduzir isso com:
- Manter a documentação versionada em Git (mesmo que em submódulos de outros repositórios: exemplo, ter um repositório centralizado apenas com documentos)
- Instruir seu agente de AI para que cada mudança pertinente no código mude também a documentação.
Repositório centralizado de documentação
Uma abordagem que funciona bem é criar um repositório separado apenas para documentação, por exemplo product-docs, e adicioná-lo como submódulo nos repositórios de código.
# No repositório do produtogit submodule add git@github.com:sua-org/product-docs.git docsA estrutura fica assim:
product-api/├── src/├── tests/├── docs/ ← submódulo apontando para product-docs│ ├── ADRs/│ ├── post-mortems/│ ├── documentations/│ └── design-systems/└── .gitmodulesAs vantagens desse abordagem:
- Documentação acessível junto ao código, mas com ciclo de vida independente. Engenheiros podem dar merge em PRs de docs sem afetar o código e vice-versa.
- Um único repositório de documentação pode ser submódulo de vários projetos. Se sua organização tem
product-api,product-webeproduct-mobile, todos compartilham o mesmoproduct-docs. - Permissões separadas. Times de produto, QA ou documentação técnica podem ter acesso de escrita ao
product-docssem precisar de acesso aos repositórios de código. - Agentes de AI operam sobre uma pasta local. Ferramentas como Claude Code podem ler e editar a documentação diretamente no submódulo, sem precisar de integrações externas.
Automatizando com Claude via CI/CD
Bem, se pode atualizar suas documentaçõs apenas pedindo aos agentes ou criando uma skill para isso. Uma forma prática de implementar o segundo requisito é usar o claude-code-action diretamente no pipeline de CI/CD. O agente roda como um step do GitHub Actions, lê o diff do PR aprovado e atualiza a documentação automaticamente.
Exemplo 1 — Atualizar o README.md após merge na main:
name: Update README.md
on: push: branches: [main]
jobs: update-docs: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 with: fetch-depth: 2
- name: Run Claude to update README.md uses: anthropics/claude-code-action@beta with: anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }} prompt: | Analise o diff do último commit (git diff HEAD~1 HEAD). Se houver mudanças relevantes de arquitetura, novos comandos, dependências ou convenções de código, atualize o README.md para refletir o estado atual do projeto. Faça commit das mudanças com a mensagem "docs: update README.md [skip ci]".Exemplo 2 — Atualizar páginas no Notion após PR mergeado:
name: Update Notion Docs
on: pull_request: types: [closed] branches: [main]
jobs: sync-notion: if: github.event.pull_request.merged == true runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 with: fetch-depth: 0
- name: Sync docs to Notion via Claude uses: anthropics/claude-code-action@beta with: anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }} prompt: | Leia o diff do PR "${{ github.event.pull_request.title }}". Identifique mudanças que impactam a documentação pública (APIs, setup, arquitetura). Use a integração MCP do Notion para criar ou atualizar as páginas correspondentes. env: NOTION_TOKEN: ${{ secrets.NOTION_TOKEN }}O padrão é sempre o mesmo: PR mergeado → CI dispara → Claude lê o diff → documentação atualizada automaticamente. A diferença está apenas no destino (arquivo local, Notion ou Obsidian).
Integrações
Integração com Notion via MCP
Para quem guarda as documentações e documentos no Notion, se pode usar uma integração MCP que permite criar e modificar docuemntos via código e agentes de AI.
Isso evita o esforço de se criar textos manualmente no notion que embora tenha Ai embutida, não é tão capaz como um codex ou claude code.
O fluxo proposto:
Engineer faz mudança no código │ ▼Agente de AI lê as mudanças │ ▼Ativação do Notion MCP │ ▼Cria/atualiza página no NotionMais informações em https://developers.notion.com/guides/mcp/get-started-with-mcp
Obsidian como repositório Git
O Obsidian é a alternativa que prefiro. Diferente do Notion (cloud e fechado), o Obsidian salva documentos em uma pasta local que pode ser um repositório Git ou uma pasta normal.
Isso te dá:
- Review de diff antes de aceitar qualquer mudança de documentação
- Histórico completo de commits e versões de documentos via Git
- Knowledge graph, o Obsidian mantém um grafo de links entre documentos, o que permite que agentes naveguem entre páginas relacionadas durante uma busca. Na prática, você consegue criar um grafo de conhecimentos interdocumental no qual modelos de AI tem facilidade de explorar os contextos, afinal, um documento chama outro.
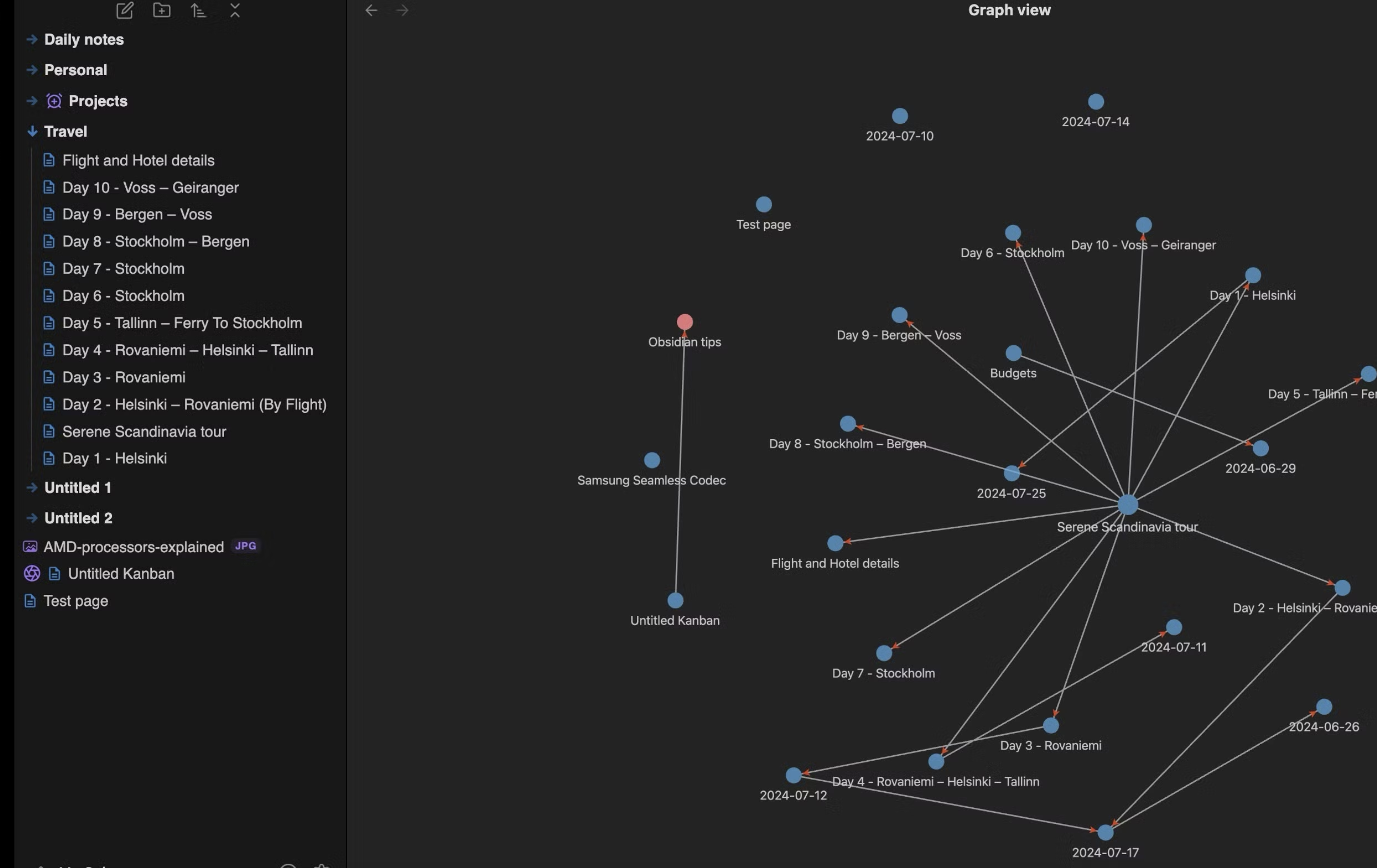
Em outras palavras, usando o obsidian, a integração com agentes como claude code é mais natural pois não é necessário API KEYS ou MCPs, é apenas um diretório. Além disso, cada documento pode ser linkado à outros pertinentes, ajudando o modelo a poupar tokens.
Resumo
A ideia central é simples: documentação que não está perto do código, não sobrevive.
AI é uma grande aliada para documentação. Hoje se pode automatizar tudo sem dificuldades em custo de tokens. Sem mais gastar horas escrevendo uma feature ou um post-mortem.