
Índice
- Overview
- Configurações de Memória
- Configurações de Conexão e Workers
- Configurações de WAL e Checkpoint
- Configurações de Autovacuum
- Configurações de Conexão e Sessão
- Extensões Essenciais do PostgreSQL
- Connection Pooling e Conectividade
- Referências
Overview
É de conhecimento geral que o PostgreSQL é um dos bancos relacionais mais usados no mundo e sabendo disso decidi compilar neste texto algumas configurações importantes para melhorar sua eficiência.
Meu primeiro contato com muitas dessas configurações foi no desafio “Rinha de Backend” do zanfranceschi, onde os participantes competiam para criar um sistema capaz de suportar inúmeras requisições concorrentes sem gargalos ou falhas. Era um desafio que permitia tudo e muitas pessoas desabilitaram ou modificaram as configurações do Postgres para torná-lo mais eficiente (ainda que menos seguro para ambientes reais).
Na prática, tudo que apresento aqui está na documentação oficial do PostgreSQL (que li pela primeira vez para escrever este texto). Porém, é uma documentação extensa e muitas configurações têm casos de uso específicos, então considero válido sumarizar apenas as mais importantes.
O objetivo aqui não é abordar o que normalmente se aprende sobre bancos relacionais como índices, SQL, constraints e procedures, mas sim falar sobre o que ninguém me ensinou na faculdade: networking, configurações avançadas e extensões.
Sobre o Postgres
O postgreSQL ou postgres nada mais é que um banco relacional. Ele é um banco maduro e muito flexível, podendo até mesmo guardar estruturas aninhadas ou criar data_types complexos. O desempenho do PostgreSQL depende fortemente de uma configuração adequada já que as configurações padrão são conservadoras e projetadas para compatibilidade, não para desempenho.
As configurações podem ficar localizadas em um arquivo postgresql.conf como no exemplo abaixo de um servidor de 16GB de RAM:
# Configurações de Memóriashared_buffers = 4GB # 25% da RAMwork_mem = 16MB # Memória por operação de ordenação/hashmaintenance_work_mem = 1GB # Para VACUUM, CREATE INDEXeffective_cache_size = 12GB # 75% da RAM (dica para o planejador)
# Configurações de Conexãomax_connections = 200 # Use connection pooling para maislisten_addresses = '*' # Aceitar conexões remotas
# Workers e Paralelismomax_worker_processes = 20max_parallel_workers = 12max_parallel_workers_per_gather = 4
# WAL e Checkpointwal_level = replica # Para replicaçãomax_wal_size = 4GBcheckpoint_timeout = 15mincheckpoint_completion_target = 0.9
# Autovacuumautovacuum = onautovacuum_max_workers = 4autovacuum_naptime = 30s
# Conexão e Sessãotcp_keepalives_idle = 300 # Detectar conexões mortasidle_session_timeout = 30min # Fechar sessões ociosas
# Extensõesshared_preload_libraries = 'pg_stat_statements, pg_cron'Irei abordar algumas destas configurações e o que elas significam. Claro que existem inúmeras outras, mas se fosse para listar todas, é melhor ler a documentação. A ideia é listar as mais importantes para melhorar o desempenho do seu banco.
Configurações de Memória
shared_buffers
Descrição: Cache primário do PostgreSQL. Todos os dados lidos do disco são primeiro carregados nos shared buffers, e as gravações também são preparadas aqui antes de serem salvas no disco.
Por Que Importa: Esta é a memória de trabalho do seu banco de dados. Toda operação de leitura verifica este cache primeiro. Se o cache for muito pequeno significa um cache miss alto e I/O constante no disco para buscar as informações. Se o cache for muito grande pode levar a gasto de recursos desnecessários.
Ponto Ideal: 15–25% da RAM total é o ideal segundo a literatura, mas claro que pode variar dependendo do use case.
# Para um servidor com 16GB RAMshared_buffers = 4GB
# Para um servidor com 64GB RAMshared_buffers = 16GBAlém de 25% da RAM, você obtém retornos decrescentes porque o PostgreSQL também depende do cache do sistema de arquivos do SO. O SO geralmente é melhor em cache do que o próprio buffer pool do PostgreSQL.
work_mem
Descrição: Memória alocada para operações internas e processamento. Se o workload for pesado demais e atingir este valor, para evitar erros de memória (OOM) o banco começa a processar dados no dico rígido. Lento porém evita erros. Isso é chamado de Disk Spill.
Se este valor for muito alto, o query planner pode ficar maluco e começar a fazer planos não tão eficientes pois pensa que temos muita memória.
Ponto Ideal: 4–32MB (dependente do contexto)
Por Que Importa: work_mem abaixo do esperado faz com que queries façam spill para o disco e reduz drasticamente a velocidade. work_mem acima do esperado pode ocasionar errosde OOM.
work_mem = 16MBUma única query complexa pode gerar várias operações de ordenação/hash/joins… A fórmula é:
Memória Potencial = work_mem × max_connections × operações_por_consultaCom 100 conexões, 16MB work_mem e consultas com média de 3 operações, você pode consumir 4,8GB.
maintenance_work_mem
Descrição: Memória usada para operações de manutenção como VACUUM, CREATE INDEX, ALTER TABLE e verificações de restrição FOREIGN KEY.
Padrão: 64MB
Ponto Ideal: 256MB – 2GB
Por Que Importa: Valores maiores aceleram significativamente a criação de índices, vacuum e outras tarefas de manutenção. Diferente do work_mem, geralmente apenas uma operação de manutenção é executada por vez.
# Para servidores com 16GB+ RAMmaintenance_work_mem = 1GB
# Para bancos de dados grandes (100GB+)maintenance_work_mem = 2GBIsso não afeta o desempenho normal de queries, mas melhora drasticamente a velocidade de operações em massa e manutenção de rotina.
Configurações de Conexão e Workers
max_connections
Descrição: Número máximo de conexões simultâneas ao banco de dados permitidas. Se uma aplicação encontra gargalos na comunicação entre backend e BD, talvez o problema seja baixo número de conexões simultâneas.
Padrão: 100
Ponto Ideal: 100–400 (depende muito da carga de trabalho)
Por Que Importa: Cada conexão consome memória (vários MB) para overhead de conexão. Muitas conexões criam contenção e esgotamento de recursos.
# Para aplicações web com connection poolingmax_connections = 200Um número muito alto de connections pode consumir muitos recursos e causar erros de “Too many connections”
Ao invés de ter múltiplas conexões simultâneas, talvez seja o caso de considerar usar connection pooling (PgBouncer, pgpool-II) ao invés de mais conexões. Assim, ao invés de sempre recriar as conexões (que têm overhead), você sempre mantêm as conexões ativas com um tempo de inatividade máximo para se desligar a conexão.
max_worker_processes
Descrição: Número máximo de processos worker em background que o sistema pode suportar. Este é o orçamento total para todos os workers em background.
Padrão: 8
Por Que Importa: Esta é a base para paralelismo. Queries paralelas, workers de autovacuum, workers de replicação lógica e workers em background todos usam desta pool de workers.
max_worker_processes = 16max_parallel_workers
Descrição: Número máximo de workers que podem ser usados para execução de queries paralelas em todo o sistema.
Padrão: 8
Ponto Ideal: 50–75% dos núcleos de CPU
Por Que Importa: Permite ao PostgreSQL paralelizar a execução de queries, acelerando significativamente scans grandes e agregações.
# Para um servidor de 16 núcleosmax_parallel_workers = 12Restrição: Não pode exceder max_worker_processes.
Configurações de WAL e Checkpoint
WAL -> Técnica usada pelo postgres e outros BDs para garantir durabilidade e consistência. Guarda todas mudanças feitas no banco numa lista append only antes da mudança ser aplicada. Assimse garante que uma transação feita tenha seu log gravado. Isto é importante para replicação de mudanças para replicas de banco de dados de leitura (que precisam saber o que acontecer na replica de escrita). Também é importante para disaster recovery.
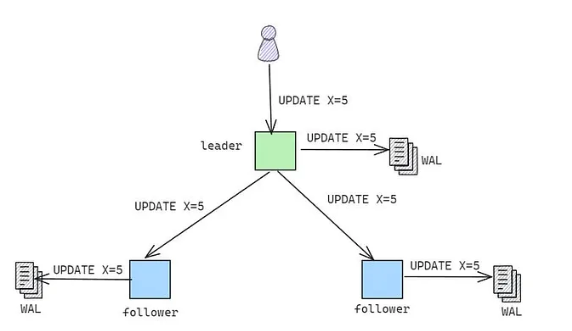
wal_level
Descrição: Determina quanta informação é escrita no Write-Ahead Log (WAL).
Padrão: replica
Ponto Ideal:
minimalpara bancos de dados standalone sem replicação (mais rápido)replicapara replicação em streaminglogicalpara replicação lógica
Por Que Importa: Níveis menores significam menos overhead de WAL mas desabilitam recursos de replicação.
# Para produção com replicaçãowal_level = replica
# Para carga em massa (temporariamente)wal_level = minimalmax_wal_size
Descrição: Tamanho máximo de arquivos WAL antes de disparar um checkpoint.
Padrão: 1GB
Ponto Ideal: 2GB – 16GB (depende do volume de escrita)
Por Que Importa: Valores maiores reduzem a frequência de checkpoint, melhorando o desempenho de escrita mas aumentando o tempo de recuperação.
# Para cargas moderadas de escritamax_wal_size = 4GB
# Para cargas pesadas de escritamax_wal_size = 8GBValores maiores significam tempo de recuperação de crash mais longo.
checkpoint_timeout
Descrição: Tempo máximo entre checkpoints automáticos do WAL.
Padrão: 5 minutos
Ponto Ideal: 10–30 minutos
Por Que Importa: Checkpoints causam picos de I/O. Checkpoints menos frequentes suavizam o I/O mas aumentam o tempo de recuperação.
# Para cargas pesadas de escritacheckpoint_timeout = 15min
# Para cargas muito pesadas de escritacheckpoint_timeout = 30minConfigurações de Autovacuum
VACUUM -> Se você deletar 10 mil linhas do seu banco, o tamanho de seu BD não muda. O que bancos como postgres fazem é marcar estas linhas como desativadas. Isso acontece pois é melhor ter uma operação de deleção/alteração rápida (deletar/alterar fisicamente pode demorar tempo). Isso é chamado de MVCC (Multi-Version Concurrency Control), onde não se sobrescreve linhas, mas cria uma nova versão a fim de evitar erros de concorrência. O que o VACUUM faz é fisicamente deletar as linhas marcadas como desativadas ou alteradas.
autovacuum
Descrição: Habilita o daemon de autovacuum para manutenção automática do banco de dados. Ou seja, automatiza o VACUUM.
Padrão: on
Ponto Ideal: on (sempre)
Por Que Importa: Autovacuum previne wraparound de ID de transação, remove tuplas mortas e atualiza estatísticas. Desabilitá-lo quase nunca é recomendado.
autovacuum = onDesabilitar o autovacuum pode levar a degradação severa de desempenho e corrupção de banco de dados (wraparound de ID de transação).
autovacuum_max_workers
Descrição: Número máximo de processos de autovacuum que podem executar simultaneamente.
Padrão: 3
Ponto Ideal: 3–6
Por Que Importa: Mais workers podem lidar com vacuum de múltiplas tabelas concorrentemente, importante para bancos de dados com muitas tabelas ativas.
# Para bancos de dados com muitas tabelasautovacuum_max_workers = 6Mais workers consomem mais recursos mas mantêm tabelas mais limpas para casos de muita escrita
autovacuum_naptime
Descrição: Atraso mínimo entre execuções de autovacuum em qualquer banco de dados.
Padrão: 1 minuto
Ponto Ideal: 30 segundos – 1 minuto
Por Que Importa: Controla com que frequência o autovacuum verifica se há trabalho.
# Para cargas pesadas de escritaautovacuum_naptime = 30sConfigurações de Conexão e Sessão
tcp_keepalives_idle
Descrição: Tempo antes de enviar um pacote TCP keepalive para detectar conexões mortas.
Padrão: 0 (usa padrão do SO, tipicamente 2 horas)
Ponto Ideal: 60–600 segundos
Por Que Importa: Detecta e fecha conexões mortas mais rapidamente, prevenindo esgotamento de slots de conexão.
# Detectar conexões mortas em 5 minutostcp_keepalives_idle = 300idle_session_timeout
Descrição: Termina automaticamente sessões que estão ociosas pela duração especificada.
Padrão: 0 (desabilitado)
Ponto Ideal: 10–60 minutos (dependente da aplicação)
Por Que Importa: Previne que conexões ociosas consumam slots de conexão indefinidamente.
# Fechar conexões ociosas por 30 minutosidle_session_timeout = 30minÚtil quando aplicações não fecham conexões adequadamente.
Extensões PostgreSQL
O sistema de extensões do PostgreSQL permite adicionar funcionalidades sem modificar o núcleo do banco de dados. Extensões são módulos pré-empacotados que podem ser instalados e habilitados por banco de dados.
Como Instalar e Habilitar Extensões
-- Verificar extensões disponíveisSELECT * FROM pg_available_extensions;
-- Habilitar uma extensãoCREATE EXTENSION IF NOT EXISTS nome_extensao;
-- Verificar extensões instaladas\dxExemplos de extensões populares
pg_trgm
Descrição: Fornece correspondência de similaridade de texto baseada em trigramas e busca full-text rápida usando índices GIN/GiST.
Casos de Uso:
- Busca fuzzy de texto (encontrar strings similares)
- Funcionalidade de autocomplete
- Busca tolerante a erros de digitação
- Consultas LIKE/ILIKE rápidas com correspondência de padrões
Por Que Importa: Habilita buscas de similaridade de alto desempenho que de outra forma exigiriam motores de busca externos. Particularmente útil para recursos de busca voltados ao usuário.
-- Habilitar a extensãoCREATE EXTENSION IF NOT EXISTS pg_trgm;
-- Criar um índice GIN para buscas de similaridade rápidasCREATE INDEX idx_users_name_trgm ON users USING GIN (name gin_trgm_ops);
-- Encontrar nomes similares (correspondência fuzzy)SELECT name, similarity(name, 'John Doe') AS simFROM usersWHERE similarity(name, 'John Doe') > 0.3ORDER BY sim DESC;
-- Correspondência de padrões rápida com suporte a índiceSELECT * FROM usersWHERE name ILIKE '%john%';
-- Encontrar registros com erros de digitaçãoSELECT * FROM productsWHERE name % 'iPone'; -- Corresponderá a 'iPhone'Funções Principais:
similarity(text, text)- Retorna pontuação de similaridade (0-1)word_similarity(text, text)- Similaridade baseada em palavrastext % text- Operador de similaridade (limite configurável)
pgvector
Descrição: Adiciona tipos de dados vetoriais e capacidades de busca de similaridade para aplicações de IA/ML, habilitando armazenamento e consulta eficientes de embeddings.
Casos de Uso:
- Busca semântica
- Sistemas de recomendação
- Busca de similaridade de imagens
- Aplicações alimentadas por IA usando embeddings do OpenAI, Cohere, etc.
Por Que Importa: Essencial para aplicações modernas de IA. Permite armazenar embeddings diretamente no PostgreSQL e realizar buscas eficientes de vizinhos mais próximos sem bancos de dados vetoriais externos.
-- Habilitar a extensãoCREATE EXTENSION IF NOT EXISTS vector;
-- Criar uma tabela com coluna vetorialCREATE TABLE documents ( id SERIAL PRIMARY KEY, content TEXT, embedding vector(1536) -- Dimensão de embedding do OpenAI ada-002);
-- Criar um índice para busca de similaridade rápidaCREATE INDEX ON documents USING ivfflat (embedding vector_cosine_ops)WITH (lists = 100);
-- Ou usar HNSW para melhor desempenho (PostgreSQL 16+)CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops);
-- Encontrar documentos similares (similaridade de cosseno)SELECT id, content, 1 - (embedding <=> '[0.1, 0.2, ...]'::vector) AS similarityFROM documentsORDER BY embedding <=> '[0.1, 0.2, ...]'::vectorLIMIT 10;
-- Operadores de distância disponíveis:-- <-> (distância L2)-- <=> (distância de cosseno)-- <#> (produto interno)pgcrypto
Descrição: Fornece funções criptográficas para criptografia, hashing e geração de dados aleatórios.
Casos de Uso:
- Hashing de senhas
- Criptografia de dados em repouso
- Geração de tokens seguros
- Criptografia/descriptografia PGP
Por Que Importa: Habilita armazenamento seguro de dados sem criptografia em nível de aplicação. Funções criptográficas integradas garantem práticas de segurança consistentes.
-- Habilitar a extensãoCREATE EXTENSION IF NOT EXISTS pgcrypto;
-- Hash de senhas (bcrypt)INSERT INTO users (email, password_hash)VALUES ('user@example.com', crypt('user_password', gen_salt('bf')));
-- Verificar senhaSELECT * FROM usersWHERE email = 'user@example.com' AND password_hash = crypt('user_password', password_hash);
-- Gerar UUIDs aleatóriosSELECT gen_random_uuid();
-- Criptografar/descriptografar dados-- Criptografia simétricaSELECT pgp_sym_encrypt('dados sensíveis', 'chave_criptografia');SELECT pgp_sym_decrypt(coluna_criptografada, 'chave_criptografia') FROM nome_tabela;
-- Gerar bytes aleatórios segurosSELECT gen_random_bytes(32);
-- Funções de hashSELECT digest('dados', 'sha256');SELECT encode(digest('dados', 'sha512'), 'hex');citext
Descrição: Tipo de texto case-insensitive que se comporta como texto regular mas com comparações e indexação case-insensitive.
Casos de Uso:
- Endereços de email
- Nomes de usuário
- Restrições únicas case-insensitive
- Busca sem penalidade de desempenho do ILIKE
Por Que Importa: Simplifica operações case-insensitive sem exigir funções LOWER() em todos os lugares. Mantém o case enquanto compara de forma case-insensitive.
-- Habilitar a extensãoCREATE EXTENSION IF NOT EXISTS citext;
-- Criar tabela com coluna case-insensitiveCREATE TABLE users ( id SERIAL PRIMARY KEY, email citext UNIQUE, -- Unicidade case-insensitive username citext NOT NULL);
-- Estes serão tratados como duplicatasINSERT INTO users (email, username)VALUES ('User@Example.com', 'JohnDoe');
-- Isto falhará (email duplicado)INSERT INTO users (email, username)VALUES ('user@example.com', 'JaneDoe');
-- Comparações case-insensitive (sem necessidade de ILIKE)SELECT * FROM users WHERE email = 'USER@EXAMPLE.COM';
-- Índice funciona com buscas case-insensitiveCREATE INDEX idx_users_email ON users(email);Benefícios Principais:
- Preserva o case original no armazenamento
- Comparações automáticas case-insensitive
- Funciona com índices B-tree
- Sem necessidade de índices funcionais em LOWER()
uuid-ossp
Descrição: Gera identificadores universalmente únicos (UUIDs) usando vários algoritmos.
Casos de Uso:
- Chaves primárias para sistemas distribuídos
- Identificadores não sequenciais
- IDs voltados ao público (URLs, APIs)
- Identificadores seguros para merge entre bancos de dados
Por Que Importa: UUIDs previnem colisão de IDs em sistemas distribuídos e ocultam padrões sequenciais. Essencial para microserviços e implantações multi-região.
-- Habilitar a extensãoCREATE EXTENSION IF NOT EXISTS "uuid-ossp";
-- Criar tabela com chave primária UUIDCREATE TABLE orders ( id UUID PRIMARY KEY DEFAULT uuid_generate_v4(), customer_id UUID NOT NULL, total DECIMAL(10,2));
-- Funções disponíveis de geração de UUID:SELECT uuid_generate_v1(); -- Baseado em tempoSELECT uuid_generate_v4(); -- Aleatório (mais comum)
-- Inserir com UUID auto-geradoINSERT INTO orders (customer_id, total)VALUES ('a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11', 99.99);Versões de UUID:
v1- Baseado em tempo (inclui endereço MAC, potencial preocupação de privacidade)v4- Aleatório (recomendado para a maioria dos casos de uso)
Trade-offs:
- Prós: Globalmente único, não sequencial, seguro para merge
- Contras: 16 bytes vs 4-8 bytes para inteiros, índices ligeiramente mais lentos
pg_cron
Descrição: Agendador de tarefas baseado em cron simples que executa dentro do PostgreSQL.
Casos de Uso:
- Limpeza periódica de dados
- Agregações agendadas
- Tarefas de manutenção automatizadas
- Geração recorrente de relatórios
Por Que Importa: Elimina necessidade de agendadores externos para tarefas centradas em banco de dados. Tarefas executam com garantias em nível de banco de dados e podem usar SQL diretamente.
-- Habilitar a extensão (requer superusuário)CREATE EXTENSION IF NOT EXISTS pg_cron;
-- Agendar uma tarefa (limpeza diária às 3 AM)SELECT cron.schedule( 'cleanup-old-logs', '0 3 * * *', 'DELETE FROM logs WHERE created_at < NOW() - INTERVAL ''90 days''');
-- Agendar agregação a cada 15 minutosSELECT cron.schedule( 'update-stats', '*/15 * * * *', 'REFRESH MATERIALIZED VIEW CONCURRENTLY user_stats');
-- Visualizar tarefas agendadasSELECT * FROM cron.job;
-- Visualizar histórico de execução de tarefasSELECT * FROM cron.job_run_detailsORDER BY start_time DESCLIMIT 10;
-- Desagendar uma tarefaSELECT cron.unschedule('cleanup-old-logs');Configuração:
Adicione ao postgresql.conf:
shared_preload_libraries = 'pg_cron'cron.database_name = 'seu_banco_dados'Sintaxe Cron:
┌───────────── minuto (0 - 59)│ ┌───────────── hora (0 - 23)│ │ ┌───────────── dia do mês (1 - 31)│ │ │ ┌───────────── mês (1 - 12)│ │ │ │ ┌───────────── dia da semana (0 - 6) (Domingo a Sábado)│ │ │ │ ││ │ │ │ │* * * * *Connection Pooling e Conectividade
Por que Connection Pooling é Importante
PostgreSQL cria um novo processo de servidor para cada conexão, que consome memória significativa e recursos. Sem connection pooling, aplicações podem rapidamente esgotar conexões disponíveis, levando a erros de “too many connections” e degradação de desempenho.
O Problema:
Exemplo: Cada conexão = ~10MB RAM + overhead de CPU100 conexões = ~1GB RAM mínimo1000 conexões = Degradação do sistemaA Solução: Connection pooling mantém um pool menor de conexões de banco de dados que são compartilhadas entre muitas conexões de aplicação sem que seja necessário a criação de uma nova conexão para uma nova transação.
PgBouncer
Descrição: Connection pool leve para PostgreSQL. A solução mais popular e amplamente usada.
Por Que Importa: PgBouncer pode lidar com milhares de conexões de cliente enquanto mantém um pool pequeno de conexões reduzindo o overhead do banco de dados.
Modos de Pooling:
-
Session Pooling: Conexão atribuída ao cliente por toda sessão
-
Transaction Pooling (Recomendado): Conexão retornada ao pool após cada transação
Exemplo de configuração (/etc/pgbouncer/pgbouncer.ini):
[databases]mydb = host=localhost port=5432 dbname=mydb
[pgbouncer]listen_addr = 127.0.0.1listen_port = 6432auth_type = md5auth_file = /etc/pgbouncer/userlist.txt
# Configurações do pool de conexõespool_mode = transactionmax_client_conn = 1000default_pool_size = 25reserve_pool_size = 5reserve_pool_timeout = 3
# Ajuste de desempenhoserver_idle_timeout = 600query_timeout = 60Pooling em Nível de Aplicação
Muitos frameworks e bibliotecas de acesso a banco de dados oferecem pooling integrado. Esta abordagem é mais simples de configurar mas menos flexível que soluções dedicadas como PgBouncer.
Node.js (pg-pool):
const { Pool } = require('pg');
const pool = new Pool({ host: 'localhost', database: 'mydb', user: 'usuario', password: 'senha', max: 20, // Máximo de conexões no pool idleTimeoutMillis: 30000, // Tempo antes de fechar conexão ociosa connectionTimeoutMillis: 2000,});
// Usoconst result = await pool.query('SELECT * FROM users WHERE id = $1', [userId]);Java (HikariCP):
HikariConfig config = new HikariConfig();config.setJdbcUrl("jdbc:postgresql://localhost:5432/mydb");config.setUsername("usuario");config.setPassword("senha");config.setMaximumPoolSize(20);config.setMinimumIdle(5);config.setIdleTimeout(300000);config.setConnectionTimeout(20000);
HikariDataSource dataSource = new HikariDataSource(config);Python (SQLAlchemy):
from sqlalchemy import create_engine
engine = create_engine( "postgresql://usuario:senha@localhost/mydb", pool_size=10, max_overflow=20, pool_timeout=30, pool_recycle=1800,)Quando usar pooling de aplicação vs PgBouncer:
- Pooling de aplicação: Aplicações simples, monolíticas, menos overhead operacional
- PgBouncer: Múltiplas aplicações, microserviços, necessidade de controle centralizado
Sinais de pool mal dimensionado:
- Pool muito pequeno: Timeouts de conexão, alta latência, filas de espera
- Pool muito grande: Alto uso de memória, contenção de CPU, muitas conexões ociosas