Índice
- Overview
- O que é um deployment?
- Rollbacks
- Estratégias de Deployment
- Como Funciona na Prática
- Resumo
- Referências
Overview
Recentemente, um SaaS de gateway de pagamento que acompanho o build in public ficou fora do ar por 1 dia durante a migração da v1 para a v2. Vários clientes ficaram impossibilitados de processar vendas. O problema? Realizaram um Big Bang deployment: desligaram a versão antiga e ligaram a nova sem deploy gradual e sem estratégia de rollback.
Isto foi o motivo de querer escrever este artigo sobre melhores maneiras de se realizar um deploy de aplicações críticas.
Aliás, uma ótima leitura que recomendo é o artigo do Matheus Fidelis, Principal Engineer do Itaú, a qual foi uma grande referência para meu próprio texto.
O que é um deployment?
Deployment é o processo de tornar uma nova versão de uma aplicação disponível para usuários finais. Isso envolve toda a parte atualização de infraestrutura e de código.
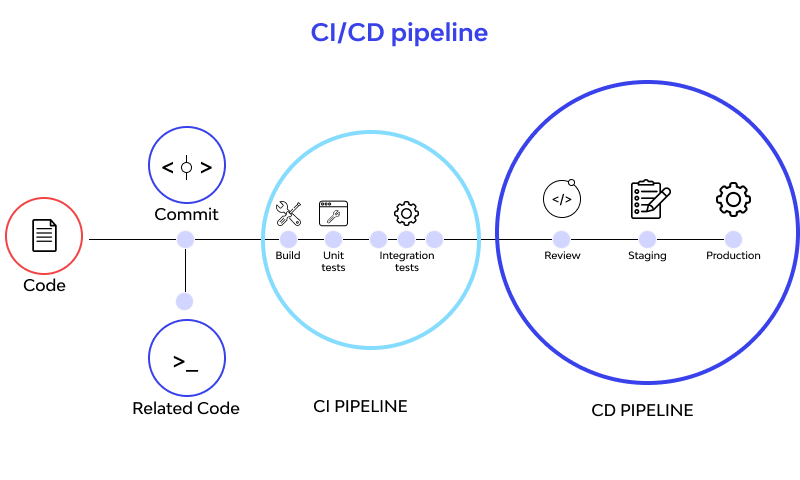
Em sistemas modernos, quando um desenvolvedor faz mudanças no código fonte, o processo de deployment passa por duas etapas:
CI (Continuous Integration): Etapa de validação. Executa testes automatizados, linting, análise de código, detecção de secrets, etc. Se algo falhar, o deploy é bloqueado.
CD (Continuous Delivery/Deployment): Etapa de deploy. Faz a compilação, build da aplicação, criação de imagens Docker e deploy para os ambientes após a etapa de CI ser concluída com sucesso. Quando o CD termina, o código fonte já se encontra em produção e disponível para os usuários.
Ferramentas comuns para implementação de CI/CD: Jenkins, GitHub Actions, GitLab CI.
Ambientes
Importante destacar que temos diferentes ambientes de código:
- Development (Desenvolvimento): Ambiente local utilizado pelos desenvolvedores. Normalmente é uma versão mais simples do sistema de produção e roda em uma única máquina single node.
- Staging (Homologação): Réplica da produção onde mudanças são testadas antes de fazer deploy para produção.
- Production (Produção): Ambiente real onde usuários finais acessam a aplicação.
Fluxo típico: Desenvolvimento → Staging → Production.
Neste artigo, quando eu falo sobre deployment eu quero dizer a transição entre Staging e Production, onde o código realmente é disponibilizado para os usuários finais.
Rollbacks
Tão importante quanto fazer deploy é desfazê-lo em caso de problemas. Rollback é o processo de reverter para uma versão estável anterior.
À medida que um sistema cresce em complexidade, é impossível cobrir todos os casos com testes ou prever todas as interações. Por isso, sistemas críticos devem ter capacidade de rollback rápido em casos de falha (2 certezas na vida: a morte e quebrar o sistema em produção).
O gateway de pagamento mencionado não tinha estratégia eficiente de rollback. Quando o problema foi identificado, não conseguiram reverter rapidamente, resultando em 1 dia de indisponibilidade.
Estratégias de Deployment
Existem diferentes estratégias de deployment, cada uma com trade-offs específicos de complexidade, consumo de recursos e tempo de rollback.
Aqui usarei uma analogia utilizada pelo Matheus Fidelis pois a acho bem didática:
Comparar um deploy de uma aplicação com uma padaria que deseja modificar a receita de seus pães
Big Bang Deployment
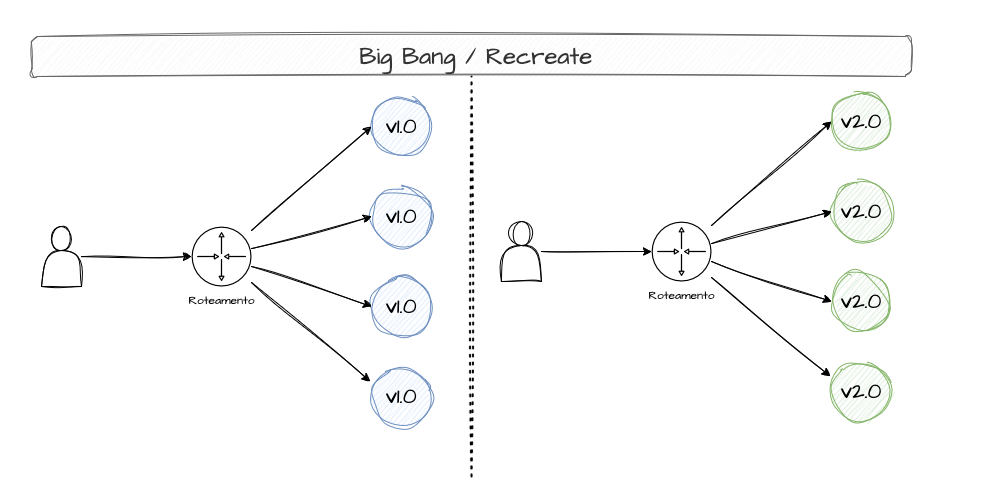
Um Big Bang Deployment ou Recreate Deployment é uma estratégia que consiste em recriar todo o sistema de forma abrupta e simultânea, sem testes intermediários ou feedback de clientes. Simplesmente trocar a versão antiga pela nova sem nenhuma transição gradual. Isso pode ser perigoso pois, caso a nova versão tenha algum erro, todos os clientes vão ser afetados.
No exemplo da padaria seria como se um padeiro trocasse a receita dos pães de um dia para o outro. Não foi feito nenhum teste de sabor ou análise de feedback. No dia seguinte, ao comprar os pães, os clientes podem não gostar da nova receita e será preciso trocar toda a produção novamente
Embora seja a maneira mais insegura de se fazer um deploy, em projetos simples ou que não podem ter 2 versões simultâneas, esta estratégia pode ser uma solução. No caso do gateway de pagamento, o Big Bang Deployment não era a melhor escolha, pois se tratava de um sistema crítico.
Blue/Green Deployment
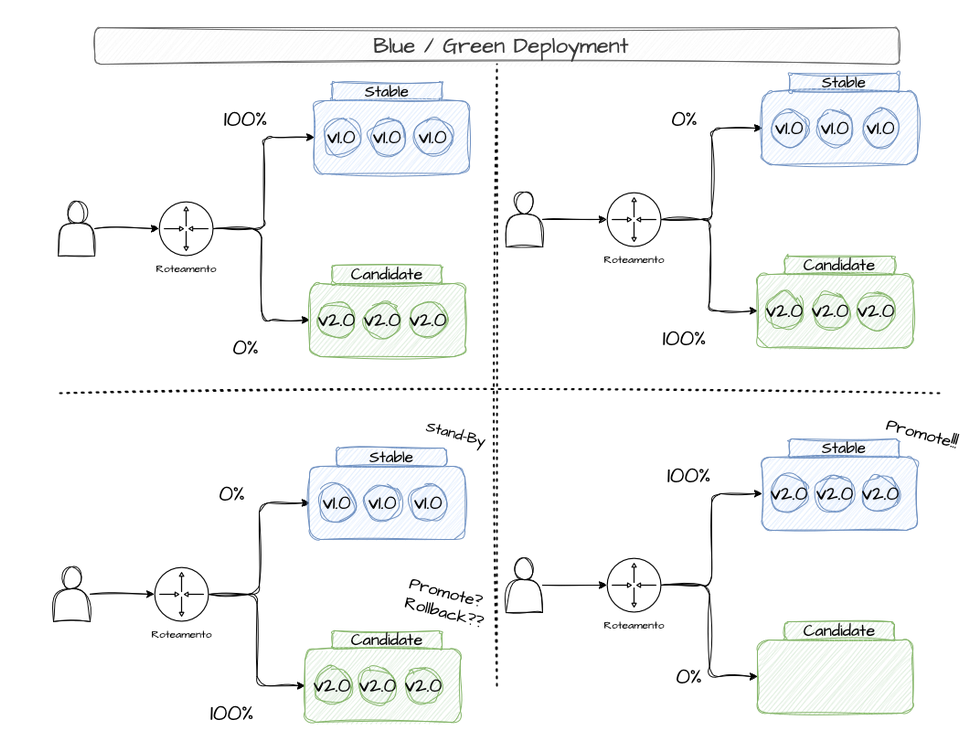
O Blue/Green Deployment é uma estratégia que prioritiza a disponibilidade durante o rollout de novas versões e um rápido rollback se necessário. No Blue/Green se mantém dois ambientes idênticos: Blue (versão atual e estável) e Green (nova versão), entenda ambiente como infraestrutura necessária para se manter um sistema em pé. Essa abordagem permite que testes sejam executados nas versões Green antes do deploy até que se tornem estáveis. Se algo der errado no processo, a versão Blue ainda está ativa e o cliente não irá notar diferença. Quando a versão Green se torna estável o suficiente, o tráfego de produção passa a versão Blue para a Green instantaneamente após mudanças de DNS. A versão Blue(estável) ainda é mantida durante um tempo para caso erros aconteçam (Neste caso basta alterar o DNS para a versão estável novamente). Se tudo der certo, as versões Blue são deletadas e As Green se tornam as estáveis.
No exemplo da padaria seria como se o padeiro preparasse 2 fornadas de pães, uma com a receita antiga e uma com a receita nova. A fornada com a receita antiga é disponibilizada para os clientes enquanto que a com a receita nova é testada pelos funcionários para saber se o gosto é bom, se os ingredientes estão corretos, se o método de produção é igual. Se a fornada com a nova receita for aceita, ela é disponibilizada para que os clientes comprem, mas, por segurança, a fornada com a receita antiga se encontra na cozinha para caso os clientes não gostem, a troca ser efetuada rapidamente
Existem desvantagens em usar o blue/green deployment. Manter 2 ambientes idênticos consome recursos e aumenta a complexidade para manter 2 versões ao mesmo tempo, especialmente em sistemas complexos.
Canary Release
A Canary Release é um deployment gradual onde a nova versão do sistema é liberada apenas para uma pequena porcentagem de usuários. Se tudo correr bem, a porcentagem aumenta progressivamente. O tráfego de produção portanto se divide entre a versão antiga (estável) e a nova versão chamada de canary (daí o nome Canary Release).
Caso a versão canary tenha erros, só uma pequena parte dos usuários sofrerá com o erro e o rollback é mais fácil. Após a confirmação de que a versão canary está estável, todo o tráfego de produção é direcionado a ela. Um exemplo de canary release seria:
- Criar uma nova feature e liberar apenas para 1% dos usuários.- Observar o comportamento dos usuários. Se nada der errado, liberar a nova feature para 5% dos usuários- Observar o comportamento dos usuários. Se nada der errado, liberar a nova feature para 20% dos usuários- ...- Liberar a nova feature para 100% dos usuáriosOu ainda um outro exemplo como:
- Liberar a nova feature para os usuários nivel 1- Observar o comportamento dos usuários. Se nada der errado, liberar a nova feature para os usuários nível 2- ...- Liberar a nova feature para todos os usuários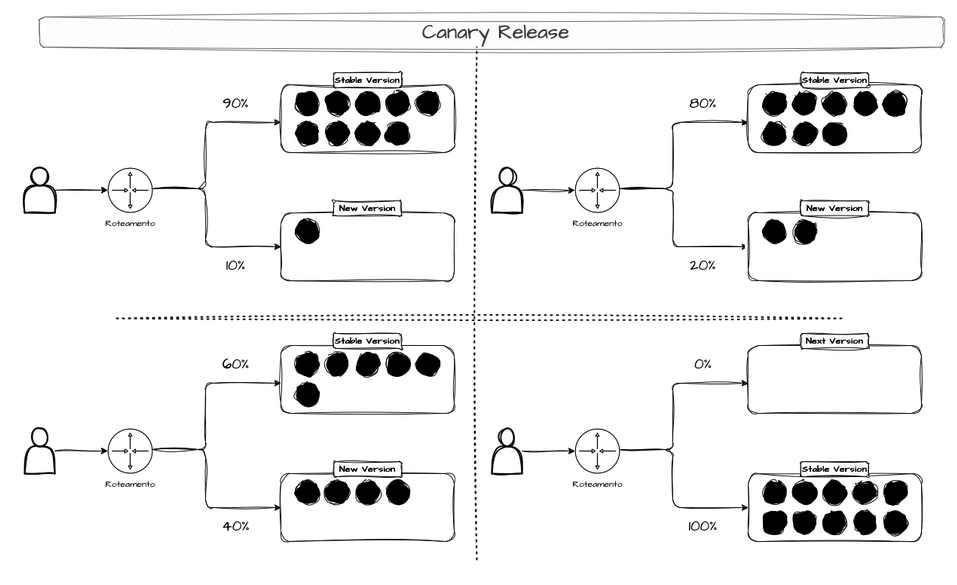
No exemplo da padaria seria como se o padeiro preparasse novos pães com uma nova receita e os adicionasse em pouca quantidade junto com os pães da receita antiga para validar se os clientes gostam. Se nenhum reclamar, cada vez mais pães com a nova receita são adicionados com calma e atenção ao feedback. Este processo pode demorar dias ou semanas, até que todos os pães sejam da nova receita. Se caso houverem reclamações, pode-se voltar à versão antiga
Esse tipo de deploy é usado por grandes empresas como netflix para validar o máximo possível se as mudanças estão corretas. Se algo der errado, o impacto é menor.
Entretando existem desvantagens nessa estratégia como: Tempo de deploy extenso, ter que manter 2 versões de um mesmo sistema e tempo de validação e observabilidade.
Rolling Updates
Essa estratégia de deployment promove uma atualização gradual da versão de um sistema e assim que estiverem estáveis, se desliga as versões anteriores.
No exemplo da padaria seria como se o padeiro preparasse novos pães com uma nova receita e conforme os pães fossem sendo comprados pelos clientes, a reposição seria realizada com os novos pães até que todos os pães sejam da nova receita
Aqui há muita confusão sobre as diferenças entre rolling updates, canary releases e blue/green deployment. No rolling updates, não há validações intermediárias e não há controle refinado de tráfego. O que temos é apenas mudanças de versões.
Um exemplo seria: Supondo que nossa aplicação precise sempre de ter 8 replicas, como atualizar da versão 1 (v1) para a versão 2 (v2)? Como rolling updates, podemos atualizar X replicas por vez.- Temos 8 replicas de uma aplicação na v1.- Temos 6 replicas de uma aplicação na v1 e 2 replicas na v2.- Temos 4 replicas de uma aplicação na v1 e 4 replicas na v2.- Temos 2 replicas de uma aplicação na v1 e 6 replicas na v2.- Temos 8 replicas de uma aplicação na v2Para que evitar 1 durante a atualização de duas replicas a aplicação esteja disponível, se criaria 2 replicas extras para sempre garantir que no mínimo tenhamos 8 réplicas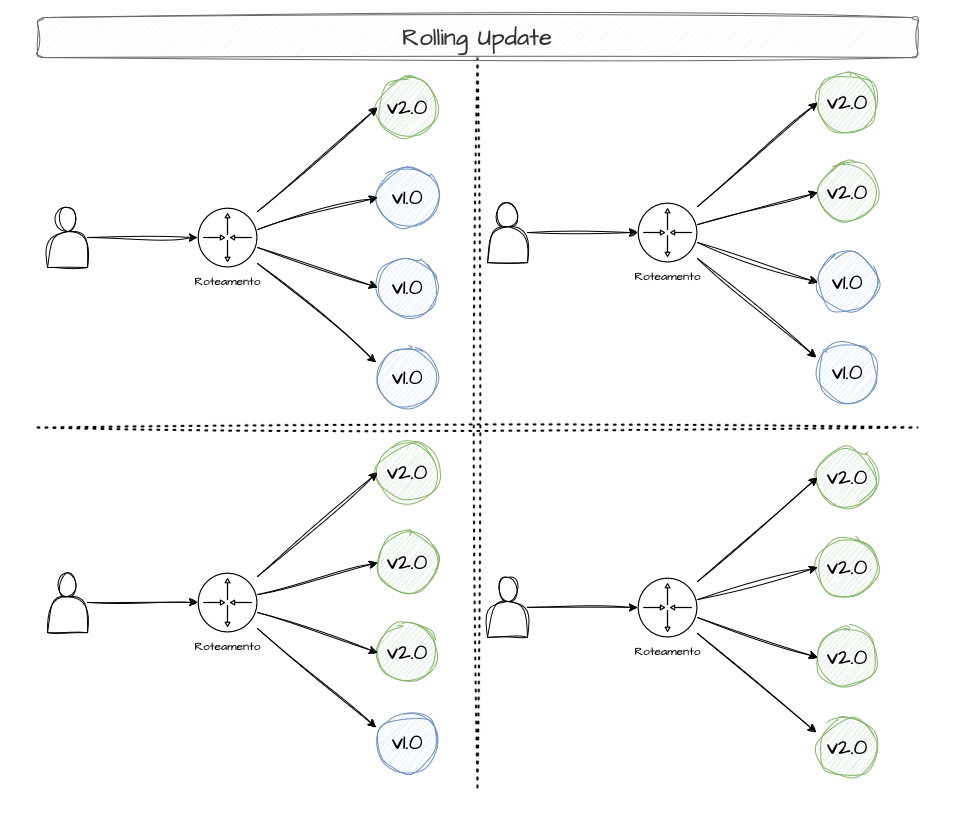
Feature Flags (Feature Toggles)
Aqui se faz deploy de código com funcionalidades desabilitadas. Essas funcionalidades são ativadas/desativadas via configuração (flags).
Um exemplo: suponhamos que queremos testar uma nova feature de pagamento para clientes VIP. O código atualizado já possui toda a lógica dessa feature, mas está desativado por uma flag. Quando queremos que a nova funcionalidade esteja em funcionamento, apenas ativamos esta flag e o código libera a implementação que já existia.
Ou seja, feature flags permitem o rollout de novas funcionalidades de forma controlada. Após se ativar uma funcionalidade se observa o comportamento dos usuários ou possíveis erros. Caso algo dê errado, basta desativar a flag novamente via configuração (sem deploys extras ou rollbacks).
Feature flags são muito amplas e podem ser usadas para testar funcionalidades segmentadas por tipos de clientes, categorias, serviços e etc.
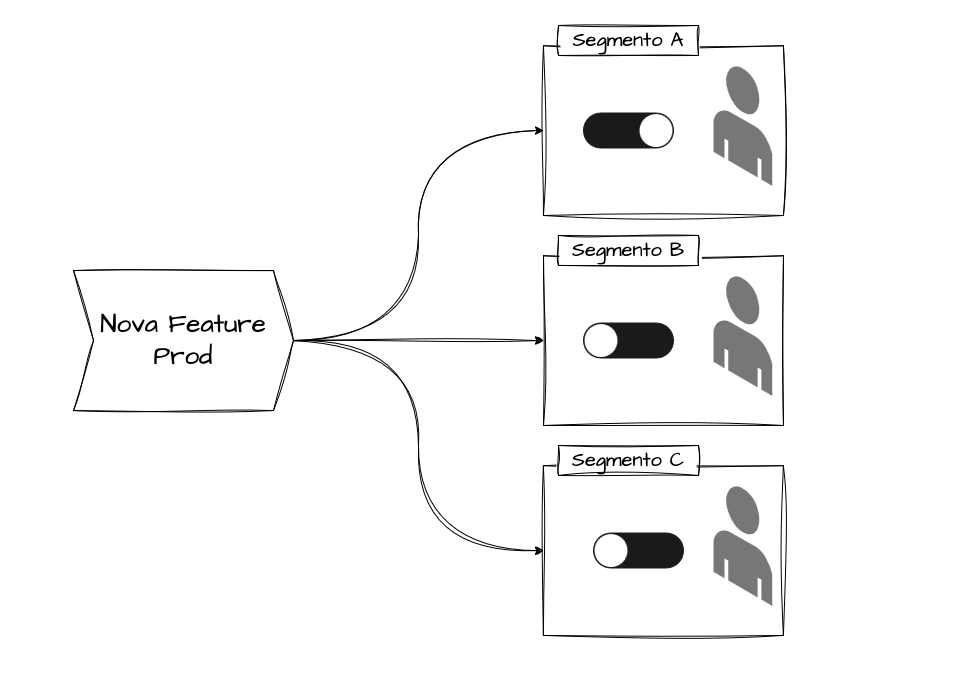
Como funciona uma feature flag?
Uma feature flag funciona através de uma consulta que a aplicação faz (em tempo de execução) para decidir se executa ou não um determinado trecho de código. Existem diferentes formas de implementar essa consulta:
1. Servidor Centralizado (Remote Config): A aplicação consulta um servidor externo para verificar o estado das flags:
// A cada requisição ou periodicamente, consulta o servidorconst flagStatus = await fetch('https://feature-flags.api.com/flags/new_checkout');if (flagStatus.enabled) { // executa novo código}Vantagens: Mudanças instantâneas sem redeploy, controle centralizado.
Desvantagens: Depende de serviço externo, latência adicional.
2. Arquivo de Configuração (Config File): A aplicação lê um arquivo local que pode ser atualizado sem redeployment:
features: new_checkout: true ai_recommendations: falseVantagens: Sem dependências externas, mais rápido.
Desvantagens: Requer acesso ao servidor para atualizar o arquivo.
3. Variáveis de Ambiente: Configuração via environment variables que são lidas na inicialização:
FEATURE_NEW_CHECKOUT=trueFEATURE_AI_RECOMMENDATIONS=falseVantagens: Simples, padrão em muitas plataformas (Heroku, Docker).
Desvantagens: Requer restart da aplicação para mudar.
4. Feature Flag Services (Split.io, LaunchDarkly, etc): Plataformas especializadas que oferecem SDKs para gerenciar flags com recursos avançados como targeting (segmentação por usuário, país, etc), rollout gradual, métricas e A/B testing. Essas plataformas mantêm um servidor que a aplicação consulta para saber o estado das flags.
Como Funciona na Prática
Se eu disser que sei como implementar cada um destes modos de deployment em todo tipo de sistema e arquitetura eu estaria mentindo. Mas, para não ficar somente na teoria, podemos ver como configurar diferentes tipos de deployment utilizando Kubernetes.
Kubernetes
O que é Kubernetes? É uma plataforma de orquestração de containers que automatiza o deploy, escalonamento e gerenciamento de aplicações containerizadas.
Conceitos básicos:
- Pod: É a menor unidade no Kubernetes. Um pod roda um ou mais containers da sua aplicação.
- Deployment: É a configuração que diz ao Kubernetes como sua aplicação deve rodar (quantas replicas, qual versão, modo de deploy, etc).
- Réplica: É uma cópia da sua aplicação rodando em um pod. Se você tem 10 réplicas, significa 10 pods rodando sua aplicação.
- Service: É a configuração responsável pelo tráfego de requisições utilizados pelo kubernetes e acesso à internet ou outros serviços Existem muitos outros conceitos, mas acho q estes são os principais para se entender os códigos abaixo.
Rolling Updates (Default do Kubernetes)
apiVersion: apps/v1 # Versão da API do Kubernetes que estamos usandokind: Deployment # Tipo de recurso: um Deployment (configuração de deploy)metadata: name: my-app # Nome do nosso deploymentspec: replicas: 10 # Queremos 10 cópias (pods) da aplicação rodando strategy: type: RollingUpdate # Estratégia: usar rolling updates rollingUpdate: maxSurge: 2 # Máximo de pods EXTRAS durante atualização (pode ter 12 no total) maxUnavailable: 1 # Máximo de pods que podem ficar indisponíveis (mínimo de 9) template: # Template: como cada pod deve ser criado spec: containers: - name: app # Nome do container dentro do pod image: my-app:v2.0 # Imagem Docker que será usada (versão 2.0 da nossa app) readinessProbe: # Teste de saúde: K8s só roteia tráfego se este teste passar httpGet: path: /health # Faz uma requisição GET em /health port: 8080 # Na porta 8080 initialDelaySeconds: 5 # Espera 5 segundos antes do primeiro teste periodSeconds: 5 # Testa a cada 5 segundosExplicação:
Imagine que você tem 10 pods rodando a versão 1.0 da sua aplicação. Quando você faz deploy da versão 2.0:
-
Kubernetes cria 2 novos pods com a versão 2.0 (maxSurge: 2)
- Agora você tem: 10 pods v1.0 + 2 pods v2.0 = 12 pods no total
-
Kubernetes testa se os novos pods estão saudáveis
- Faz requisições para
/healthnos novos pods - Só continua se receberem resposta HTTP 200 (sucesso)
- Faz requisições para
-
Remove 1 pod antigo da versão 1.0 (maxUnavailable: 1)
- Agora você tem: 9 pods v1.0 + 2 pods v2.0 = 11 pods no total
-
Repete o processo até que todos os 10 pods sejam da versão 2.0
- Cria mais pods v2.0 → testa saúde → remove pods v1.0
- O ciclo continua de forma gradual e controlada
Garantia de disponibilidade: Em nenhum momento temos menos de 9 pods rodando (10 - maxUnavailable). Isso garante que sua aplicação continue atendendo requisições durante o deploy
Comandos para aplicar e gerenciar:
# Aplica as mudanças definidas no arquivo YAMLkubectl apply -f deployment.yaml
# Acompanha o progresso do rollout em tempo realkubectl rollout status deployment/my-app
# Faz rollback para a versão anterior se algo der erradokubectl rollout undo deployment/my-appBlue/Green com Kubernetes
No Blue/Green, mantemos dois deployments completos rodando ao mesmo tempo e um Service que decide qual recebe o tráfego.
O que é um Service? É como um “porteiro” que recebe todas as requisições dos usuários e decide para qual pod encaminhar. Ele usa labels (etiquetas) para saber quais pods escolher.
# ========================================# DEPLOYMENT BLUE (Versão Atual - v1.0)# ========================================apiVersion: apps/v1kind: Deploymentmetadata: name: my-app-blue # Nome do deployment blue labels: version: bluespec: replicas: 5 # 5 pods rodando a versão antiga template: metadata: labels: app: my-app # Label que identifica a aplicação version: blue # Label que identifica como versão blue spec: containers: - name: app image: my-app:v1.0 # Versão 1.0 (antiga/estável)
---# ========================================# DEPLOYMENT GREEN (Nova Versão - v2.0)# ========================================apiVersion: apps/v1kind: Deploymentmetadata: name: my-app-green # Nome do deployment green labels: version: greenspec: replicas: 5 # 5 pods rodando a nova versão template: metadata: labels: app: my-app # Mesma label de app version: green # Label que identifica como versão green spec: containers: - name: app image: my-app:v2.0 # Versão 2.0 (nova/em teste)
---# ========================================# SERVICE (Controlador de Tráfego)# ========================================apiVersion: v1kind: Servicemetadata: name: my-app-servicespec: selector: app: my-app # Seleciona pods com label "app: my-app" version: blue # E com label "version: blue" # RESULTADO: Todo tráfego vai para os pods BLUE ports: - port: 80 # Service escuta na porta 80 targetPort: 8080 # Encaminha para porta 8080 dos podsComo funciona o switch Blue → Green:
# Passo 1: Criar o deployment GREEN (nova versão)# Isso cria 5 novos pods com v2.0, mas NENHUM tráfego vai para eles aindakubectl apply -f deployment-green.yaml
# Passo 2: Testar o GREEN internamente antes de liberar# Cria um túnel local para acessar o green sem passar pelo Servicekubectl port-forward deployment/my-app-green 8080:8080# Agora você pode testar http://localhost:8080 e validar se está tudo OK
# Passo 3: Switch instantâneo de tráfego (BLUE → GREEN)# Muda o selector do Service de "version: blue" para "version: green"# A partir deste momento, TODO o tráfego vai para GREENkubectl patch service my-app-service -p '{"spec":{"selector":{"version":"green"}}}'
# Passo 4: Rollback se algo der errado (GREEN → BLUE)# Volta o selector para "version: blue"# O tráfego volta instantaneamente para a versão antigakubectl patch service my-app-service -p '{"spec":{"selector":{"version":"blue"}}}'
# Passo 5 (opcional): Depois que GREEN está estável, deletar BLUEkubectl delete deployment my-app-blueVisualização do fluxo:
Estado Inicial:[Usuários] → [Service: version=blue] → [5 pods BLUE v1.0] ✓ Recebendo tráfego [5 pods GREEN v2.0] ✗ Sem tráfego
Após o Switch:[Usuários] → [Service: version=green] → [5 pods BLUE v1.0] ✗ Sem tráfego (backup) [5 pods GREEN v2.0] ✓ Recebendo tráfegoCanary Release com Kubernetes
No Canary, ambas as versões recebem tráfego ao mesmo tempo, mas a nova versão (canary) recebe apenas uma pequena porcentagem. A diferença do Blue/Green é que aqui dividimos o tráfego proporcionalmente usando o número de réplicas.
Como funciona a divisão de tráfego? O Service distribui requisições de forma balanceada entre TODOS os pods que têm a label app: my-app. Se temos 9 pods stable + 1 pod canary = 10 pods totais, então aproximadamente 10% do tráfego vai para o canary.
# ========================================# DEPLOYMENT STABLE (Versão Estável - v1.0)# ========================================apiVersion: apps/v1kind: Deploymentmetadata: name: my-app-stablespec: replicas: 9 # 9 pods = 90% do tráfego (9 de 10 total) template: metadata: labels: app: my-app # Label compartilhada com canary track: stable # Label específica para identificação spec: containers: - name: app image: my-app:v1.0 # Versão 1.0 (estável)
---# ========================================# DEPLOYMENT CANARY (Nova Versão - v2.0)# ========================================apiVersion: apps/v1kind: Deploymentmetadata: name: my-app-canaryspec: replicas: 1 # 1 pod = 10% do tráfego (1 de 10 total) template: metadata: labels: app: my-app # Mesma label, Service escolhe ambos track: canary # Label específica para identificação spec: containers: - name: app image: my-app:v2.0 # Versão 2.0 (em teste com usuários reais)
---# ========================================# SERVICE (Balanceador de Tráfego)# ========================================apiVersion: v1kind: Servicemetadata: name: my-appspec: selector: app: my-app # Seleciona AMBOS: stable E canary # Não filtramos por "track", então pega os dois ports: - port: 80 targetPort: 8080Progressão gradual do Canary:
# ========================================# Fase 1: 10% canary (testando com poucos usuários)# ========================================kubectl scale deployment/my-app-canary --replicas=1 # 1 pod canarykubectl scale deployment/my-app-stable --replicas=9 # 9 pods stable# Total: 10 pods → Canary recebe ~10% do tráfego# Monitorar logs, métricas, erros. Se tudo OK, avançar
# ========================================# Fase 2: 50% canary (confiança aumentando)# ========================================kubectl scale deployment/my-app-canary --replicas=5 # 5 pods canarykubectl scale deployment/my-app-stable --replicas=5 # 5 pods stable# Total: 10 pods → Canary recebe ~50% do tráfego# Continuar monitorando. Se ainda estável, finalizar
# ========================================# Fase 3: 100% canary (nova versão se torna a padrão)# ========================================kubectl scale deployment/my-app-canary --replicas=10 # 10 pods canarykubectl scale deployment/my-app-stable --replicas=0 # 0 pods stable# Total: 10 pods → Canary recebe 100% do tráfego# Após confirmação, renomear canary para stable e deletar o deployment antigo
# ========================================# Rollback em caso de problema (qualquer fase)# ========================================kubectl scale deployment/my-app-stable --replicas=10 # Volta stable para 100%kubectl scale deployment/my-app-canary --replicas=0 # Remove canaryVisualização da progressão:
Fase 1 (10%):[Usuários] → [Service] → [9 pods STABLE v1.0] ← 90% do tráfego [1 pod CANARY v2.0] ← 10% do tráfego
Fase 2 (50%):[Usuários] → [Service] → [5 pods STABLE v1.0] ← 50% do tráfego [5 pods CANARY v2.0] ← 50% do tráfego
Fase 3 (100%):[Usuários] → [Service] → [0 pods STABLE v1.0] [10 pods CANARY v2.0] ← 100% do tráfegoVantagem: Se a v2.0 tiver um bug crítico, apenas 10% dos usuários são afetados na Fase 1. Com Blue/Green, seria 100%
Feature Flag Platforms
Feature flags não dependem do Kubernetes ou de infraestrutura específica. Eles são implementados no código da aplicação e controlados por configuração externa.
Como funciona? Você faz deploy do código com TODAS as funcionalidades (antiga e nova), mas usa condicionais (if/else) para decidir qual executar baseado em uma flag. Essa flag pode ser mudada sem precisar fazer um novo deploy.
Split.io (Plataforma Profissional)
Split.io é uma plataforma SaaS que gerencia feature flags de forma centralizada. Oferece dashboard, métricas, targeting avançado e rollout gradual.
# Python - Exemplo de uso do Split.iofrom splitio import get_factory
# Conecta com a plataforma Split.io usando sua API keyfactory = get_factory('YOUR_SDK_KEY')split = factory.client()
# Definir atributos do usuário para targeting (direcionamento)# Você pode ativar features só para usuários premium, países específicos, etc.attributes = { 'user_id': '12345', # ID único do usuário 'premium': True, # É usuário premium? 'country': 'BR' # País do usuário}
# Pergunta ao Split.io: a feature 'new_recommendation_engine' está ON ou OFF# para este usuário específico?treatment = split.get_treatment('user-12345', 'new_recommendation_engine', attributes)
# Baseado na resposta, executa código diferenteif treatment == 'on': # Feature ATIVADA: usa o novo motor de IA recommendations = get_ai_recommendations()elif treatment == 'off': # Feature DESATIVADA: usa o sistema antigo recommendations = get_legacy_recommendations()else: # Fallback de segurança caso Split.io esteja fora do ar recommendations = get_default_recommendations()Exemplo de uso real:
- Você faz deploy do código acima para produção
- No dashboard do Split.io, você configura: “ativar para 10% dos usuários premium do Brasil”
- Split.io decide qual usuário vê a nova feature, você só monitora as métricas
- Se funcionar bem, aumenta gradualmente para 25%, 50%, 100%
Feature Flags Simples (Implementação Própria)
Para projetos menores ou casos simples, você pode implementar seu próprio sistema de feature flags sem plataformas externas:
Exemplo 1: Feature Flag Simples (On/Off)
features: new_checkout: true # true = ativado, false = desativado dark_mode: falseconst fs = require('fs');const yaml = require('js-yaml');
// Carrega o arquivo de configuraçãofunction loadConfig() { const file = fs.readFileSync('./config/features.yaml', 'utf8'); return yaml.load(file);}
// Verifica se uma feature está ativadafunction isEnabled(flagName) { const config = loadConfig(); return config.features[flagName] || false;}
// Uso no códigoif (isEnabled('new_checkout')) { renderNewCheckout(); // Nova versão} else { renderOldCheckout(); // Versão antiga}Vantagens:
- Extremamente simples
- Mudança instantânea: edite o YAML e salve
- Rollback: mude
trueparafalse
Resumo
A escolha da estratégia de deployment depende do contexto: criticidade da aplicação, recursos disponíveis, e tolerância a risco. Aplicações críticas devem evitar Big Bang e preferir estratégias com rollback rápido como Blue/Green ou Feature Flags.
O caso do gateway de pagamento demonstra as consequências de não ter uma estratégia adequada. Com Blue/Green, Rolling Updates ou Canary, o impacto teria sido drasticamente menor.