
Índice
- Overview
- Porque testar dados?
- Como adicionar qualidade de dados em uma pipeline
- Tipos de testes
- Testes unitários
- WAP - Write, Audit and Publish
- Onde aplicar testes?
- Dashboard de qualidade e log tables
- Resumo
Overview
Primeiro é importante notar que embora os conceitos de qualidade de dados sejam imutáveis, existem inúmeras maneiras diferentes de implementar checks de qualidade de dados, estes dependendo de variáveis como:
- Tipo de ingestão e precessamento de dados: batch, micro batch, streaming;
- Volumetria dos dados: O jeito de se testar uma tabela de 1 bilhão de linhas requer mais otimizações do que uma tabela de 500 mil linhas;
- Ferramentas: Diferentes ferramentas possuem diferentes sintaxes e modos de se adicionar testes.
Portanto, esse artigo se foca nos conceitos de fundação, mas para que não fique teórico demais, mostrarei exemplos utilizando DBT. DBT é uma ferramenta que nos permite criar tabelas utilizando SQL e guardar documentações e testes em um arquivo .yml.
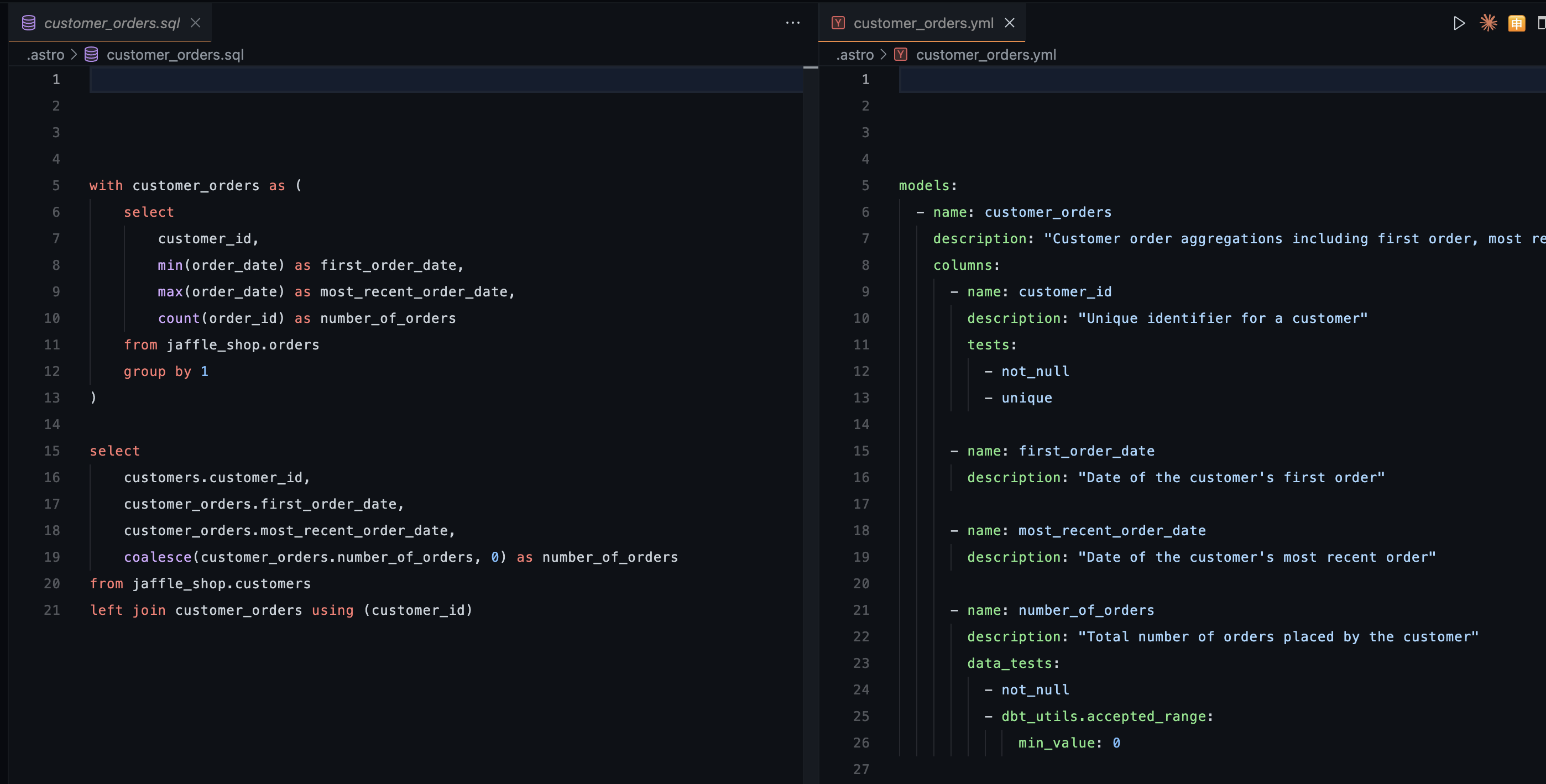
Como pode-se ver abaixo, estou criando a tabela customer_orders utilizando um arquivo SQL a partir da tabela jaffle_shop e a documentação dessa tabela juntamente com os testes se encontram num arquivo .yml.
Porque testar dados?
A resposta é meio óbvia. Não queremos que clientes ou indivíduos tomem decisões erradas baseados em dados errados. Além disso, erros nos dados podem ocasionar em:
- Perda de confiança e autoridade;
- Problemas legais ou possívels ações judiciais;
- Bugs e sistemas fora de funcionalidade;
Entre outros…
Como adicionar qualidade de dados em uma pipeline
Bem, primeiro temos de saber os tipos de testes que podemos fazer, onde e quando fazer. Isso depende de produto, complexibilidade e regra de negócio. Um sistema simples não necessariamente precisa de um ambiente extremamente robusto e testável. Devemos lembrar sempre que testar dados requer recursos: CPU, memória e especialemente tempo. Portanto, cabe à quem desenvolver uma pipeline quais testes fazer.
Tipos de testes
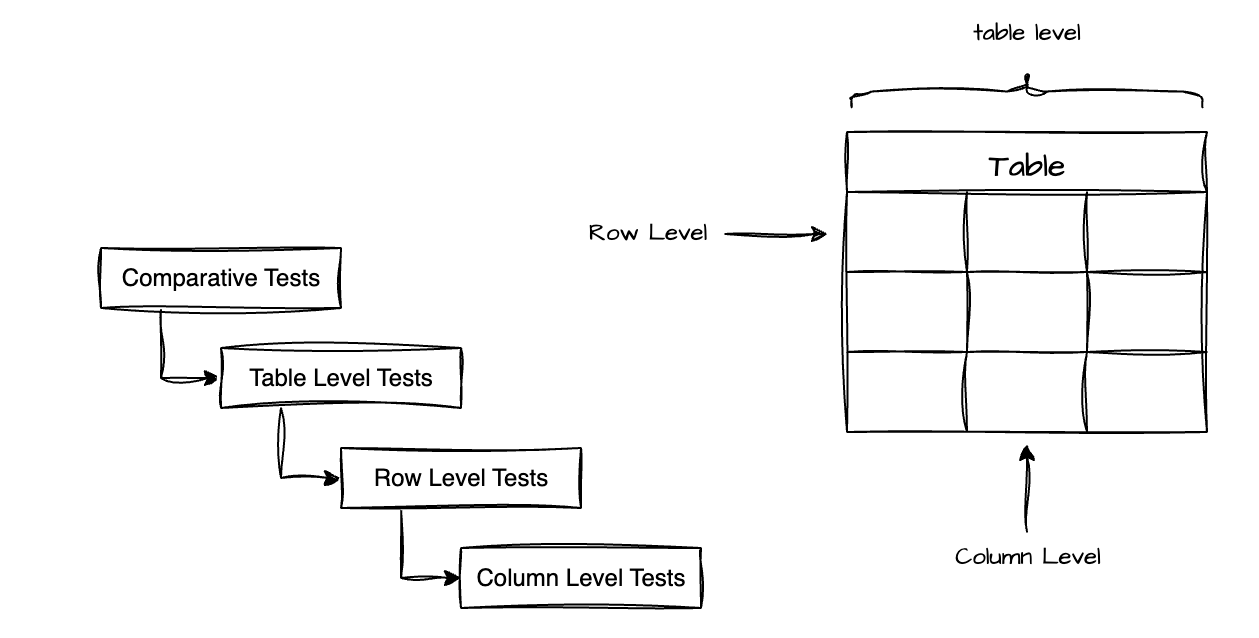
Pessoalmente, eu gosto de separar os testes em 4 níveis: testes comparativos (comparative), testes de tabela (table level), testes de linha (row level) e testes de coluna (column level).
Column level
Aqui testamos valores de colunas específicas. Alguns exemplos são:
- Teste de unicidade: Garante que cada valor em uma coluna apareça apenas uma vez, prevenindo duplicações indesejadas. Embora primary keys já tenham unicidade por definição, este teste é essencial para chaves naturais (como CPF, email) e identificadores únicos (UIDs) que precisam ser únicos por regra de negócio. Por exemplo, se dois clientes compartilharem o mesmo email, isso pode indicar cadastro duplicado ou erro na ingestão de dados.
DBT example:- name: customer_email description: Email do cliente. Deve ser único para evitar duplicação de cadastros tests: - unique- Teste de nulidade: Valida se colunas obrigatórias contêm valores nulos, garantindo a integridade dos dados essenciais. Este teste é fundamental para campos que são críticos para o negócio ou para o funcionamento de sistemas downstream. Por exemplo, um cadastro de usuário sem email pode impedir envio de notificações importantes, ou uma transação sem data pode impossibilitar análises temporais.
DBT example:- name: customer_email description: Email do cliente. Campo obrigatório para comunicação tests: - not_null- Teste de valores aceitáveis: Verifica se os valores de uma coluna estão dentro de um conjunto ou intervalo permitido, prevenindo dados inválidos ou inconsistentes. Este teste é crucial para colunas com valores categóricos (status, tipos, categorias) ou para validar ranges lógicos. Exemplos práticos: uma coluna booleana deve conter apenas true/false, ano de nascimento não pode ser maior que o ano atual, status de pedido deve ser apenas ‘placed’, ‘shipped’, ‘completed’ ou ‘returned’ - qualquer valor fora destes indica erro de sistema ou manipulação incorreta de dados.
DBT example:- name: order_status description: Keep the order status. Possible values are: placed, shipped, completed, returned tests: - accepted_values: arguments: values: ['placed', 'shipped', 'completed', 'returned']
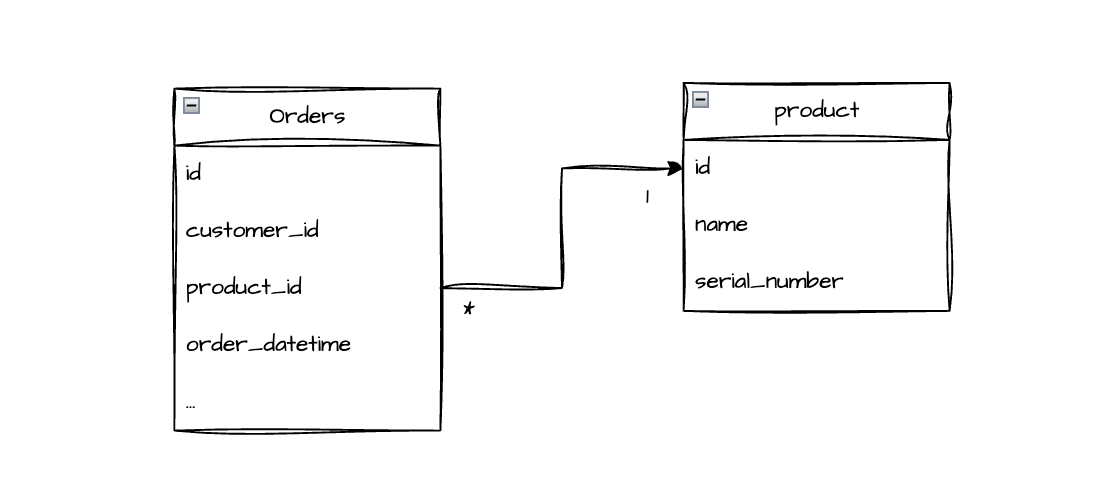
- name: monthly_sms_count description: Count of SMS sent per month tests: - dbt_expectations.expect_column_values_to_be_between: min_value: 800 max_value: 1200- Teste de integração (Referential Integrity): Garante que relacionamentos entre tabelas sejam válidos, verificando se foreign keys referenciam registros existentes nas tabelas pai. Este teste é fundamental para manter a integridade referencial do banco de dados. Por exemplo, em uma tabela
orderscom colunaproduct_id, cada ID deve corresponder a um produto existente na tabelaproducts. Se encontrarmos umproduct_idórfão (sem correspondente), isso indica dados corrompidos, possivelmente uma compra de produto deletado ou não cadastrado, erro em cascata de deleções, ou falha na sincronização entre sistemas.
DBT example:- name: product_id description: Reference to product table tests: - relationships: to: ref('products') field: idRow level
- Teste de consistência: Valida a coerência lógica entre múltiplas colunas da mesma linha, garantindo que os dados fazem sentido quando analisados em conjunto. Este teste captura inconsistências que passariam despercebidas em validações de colunas individuais. Exemplos práticos: um pedido com status ‘completed’ deve obrigatoriamente ter uma data em
completed_atpreenchida; o campototaldeve ser matematicamente igual asubtotal + impostos; uma data de fim não pode ser anterior à data de início. Esses testes previnem estados impossíveis ou logicamente inválidos nos dados.
DBT example (using dbt-utils package):tests: - dbt_utils.expression_is_true: expression: "NOT (status = 'completed' AND completed_at IS NULL)" name: completed_orders_must_have_completion_date - dbt_utils.expression_is_true: expression: "total = subtotal + tax" name: total_equals_subtotal_plus_taxTable level
- Teste de granularidade: Define e valida o nível de detalhe esperado em cada linha da tabela, prevenindo duplicações indesejadas. Cada tabela possui uma “grain” (granularidade) que determina o que cada linha representa. Por exemplo, em uma tabela
orders, cada linha pode representar “um produto comprado por um cliente em um determinado momento por um valor específico”. Neste caso, a combinação (customer_id,product_id,order_datetime,total_value) deve ser única, se duas linhas têm exatamente os mesmos valores, provavelmente são duplicatas. Ponto importante: não inclua o ID auto-gerado neste teste, pois duplicatas verdadeiras teriam campos de negócio idênticos mas IDs diferentes, fazendo o teste não detectar o problema. Este teste garante que você entende e mantém a granularidade correta conforme a regra de negócio.
DBT example (using dbt-utils package):
- name: customer_orders description: "Customer order aggregations including first order, most recent order, and total order count" columns: tests: - dbt_utils.unique_combination_of_columns: combination_of_columns: - order_datetime - total_value - customer_id - product_id- Teste de freshness (Frescor dos dados): Monitora se os dados estão sendo atualizados conforme esperado, detectando quebras silenciosas na ingestão ou processamento. Este teste é crítico para pipelines com cadências definidas (diária, horária, em tempo real). Por exemplo, se uma tabela é atualizada diariamente e de repente fica 3 dias sem receber novos dados, isso indica falha na fonte, quebra no job de ingestão, ou problemas de conectividade. Detectar isso rapidamente evita que decisões sejam tomadas com base em dados defasados.
DBT example (configured at source level in schema.yml):sources: - name: raw_data tables: - name: orders freshness: warn_after: {count: 1, period: day} error_after: {count: 3, period: day}- Teste de volumetria: Valida se o número total de registros na tabela está dentro de um intervalo esperado, detectando anomalias de volumetria. Mudanças drásticas no número de linhas frequentemente indicam problemas sérios: uma queda de 50% pode significar falha parcial na ingestão, filtros incorretos aplicados, ou perda de dados; um aumento anormal (ex: triplicar overnight) pode indicar duplicação de dados, loops infinitos, ou carga duplicada. Este teste funciona como um “sanity check” de alto nível sobre a saúde da tabela. Uma maneira de se fazer este teste é com comparative tests ou com comparações entre staging e production tables (apresentado na seção de WAP).
- Teste de paridade com source: Garante que a ingestão de dados da origem foi completa e bem-sucedida, comparando contagens de linhas entre a tabela source e a tabela de destino. Este teste é essencial em processos de ETL/ELT para validar que nenhum dado foi perdido ou duplicado durante a transferência. Se a tabela de origem tem 10.000 registros mas sua tabela ingerida tem apenas 8.500, isso sinaliza perda de dados no processo de cópia. Inversamente, ter mais linhas que a source pode indicar duplicação. Este teste valida a integridade do processo de ingestão desde a origem.
DBT example (using dbt-utils package):tests: - dbt_utils.equal_rowcount: compare_model: source('raw_data', 'orders')Testes comparativos
Testes de rastreabilidade end-to-end no ETL: Estes testes acompanham métricas-chave através de toda a pipeline, garantindo que transformações e agregações não estejam causando perda inesperada de dados. Funcionam como uma “auditoria de lineage” dos seus dados.
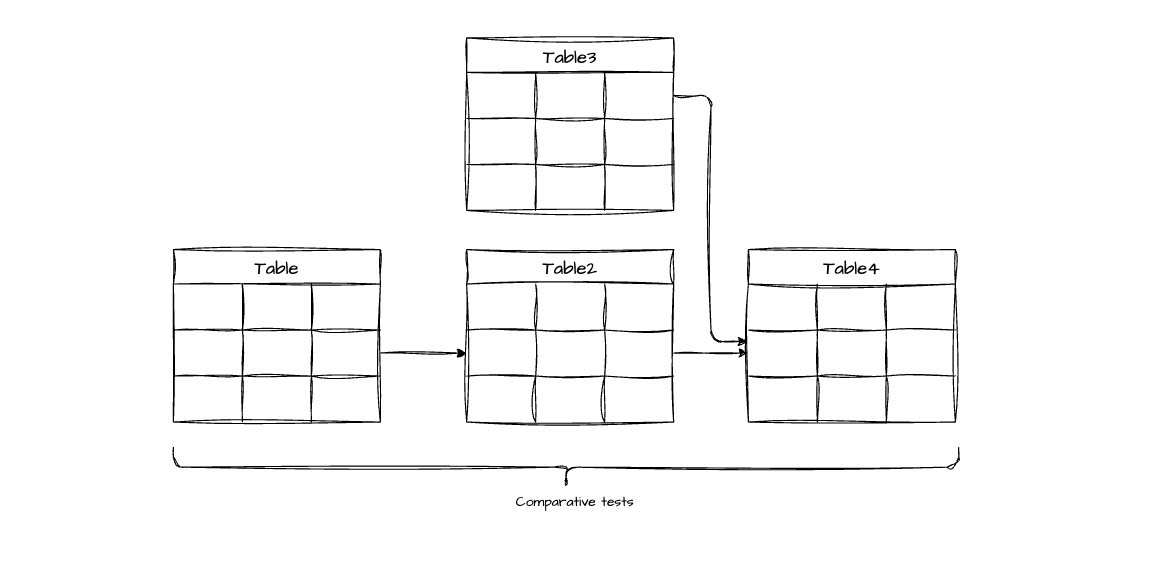
Exemplo prático: Imagine três tabelas em cascata:
pacientes(1000 pacientes)paciente_visitas(criada a partir de pacientes)paciente_observacoes(criada a partir de paciente_visitas)
A lógica: Se você tem 1000 pacientes únicos na primeira tabela, as tabelas derivadas deveriam referenciar esses mesmos 1000 pacientes (assumindo que todos os pacientes têm pelo menos uma visita/observação, ou que a lógica de negócio está clara sobre filtros).
O problema que detecta: Se paciente_observacoes de repente mostra dados de apenas 800 pacientes, você sabe que 200 pacientes “desapareceram” em algum ponto do ETL - talvez um JOIN incorreto, filtro mal aplicado, ou transformação que não considerou edge cases. Este teste força documentação e validação da lógica de negócio. Se era esperado perder esses 200 pacientes (ex: pacientes sem observações registradas), essa regra deve estar documentada e o threshold do teste ajustado adequadamente.
Um exemplo de comparative test para rastrear número de pacientes é:
WITH base_counts AS ( SELECT 'pacientes' AS tabela, COUNT(DISTINCT paciente_id) AS pacientes_unicos FROM pacientes
UNION ALL
SELECT 'paciente_visitas' AS tabela, COUNT(DISTINCT paciente_id) AS pacientes_unicos FROM paciente_visitas
UNION ALL
SELECT 'paciente_observacoes' AS tabela, COUNT(DISTINCT paciente_id) AS pacientes_unicos FROM paciente_observacoes),
base_reference AS ( SELECT pacientes_unicos AS base_count FROM base_counts WHERE tabela = 'pacientes'),
comparison_results AS ( SELECT base_counts.tabela, base_counts.pacientes_unicos, base_counts.base_count, (base_counts.pacientes_unicos - base_reference.base_count) AS diferenca, ROUND(100.0 * base_counts.pacientes_unicos / base_reference.base_count, 2) AS percentual_retencao, ROUND(100.0 * (base_reference.base_count - base_counts.pacientes_unicos) / base_reference.base_count, 2) AS percentual_perda FROM base_counts CROSS JOIN base_reference)
SELECT tabela, pacientes_unicos, base_count AS pacientes_esperados, diferenca, percentual_retencao, percentual_perda, CASE -- Threshold: permitir até 5% de perda (ajuste conforme regra de negócio) WHEN percentual_retencao >= 95.0 THEN 'Pass' WHEN percentual_retencao >= 90.0 THEN 'Warn' ELSE 'Error' END AS status_teste, CASE WHEN percentual_retencao < 95.0 THEN 'ATENÇÃO: ' || ABS(diferenca) || ' pacientes desapareceram. Verificar JOINs, filtros e transformações.' ELSE 'Pipeline mantendo integridade dos dados.' END AS diagnosticoFROM comparison_resultsORDER BY tabela;Enfim, existem diversos outros testes existentes ou testes customizados que possamos fazer. E existem bibliotecas que ajudam nisso, um exemplo de biblioteca famoso é o great expectations que possui interface para spark e dbt por exemplo. Aqui podem ver outros testes existentes:
Testes unitários
Todos nós conhecemos testes unitários em desenvolvimento de software, certo? Quando criamos uma função com lógica suficientemente complexa, devemos escrever testes para verificar se ela cobre os casos esperados (e não para provar que a função está correta, mas isso é assunto para outro artigo).
Podemos aplicar o mesmo conceito para tabelas. Durante um processo de ETL, tabelas são geradas via SQL, com tabelas upstream (dependências) e tabelas downstream (derivadas). Em muitos casos, uma query SQL é simples o suficiente para não necessitar de testes unitários. Se você é um programador ou data engineer competente, conseguirá fazer joins corretamente, case statements, window functions e outros recursos. Entretanto, existem tabelas complexas, com múltiplos joins e transformações que tornam difícil compreender seu resultado final. Nesses casos, testes unitários podem garantir que sua lógica SQL está correta.
TDD - Test Driven Development
O TDD é uma metodologia de programação onde primeiro escrevemos o teste, já conhecendo o output esperado, e depois implementamos a função. Conhecer antecipadamente o resultado esperado auxilia na criação correta da implementação. Em engenharia de dados o princípio é o mesmo: ao criar testes unitários com os resultados esperados, você consegue identificar erros no seu SQL que antes passariam despercebidos. Portanto, é uma excelente estratégia para lidar com tabelas complexas.
Um exemplo de teste unitário em dbt é:
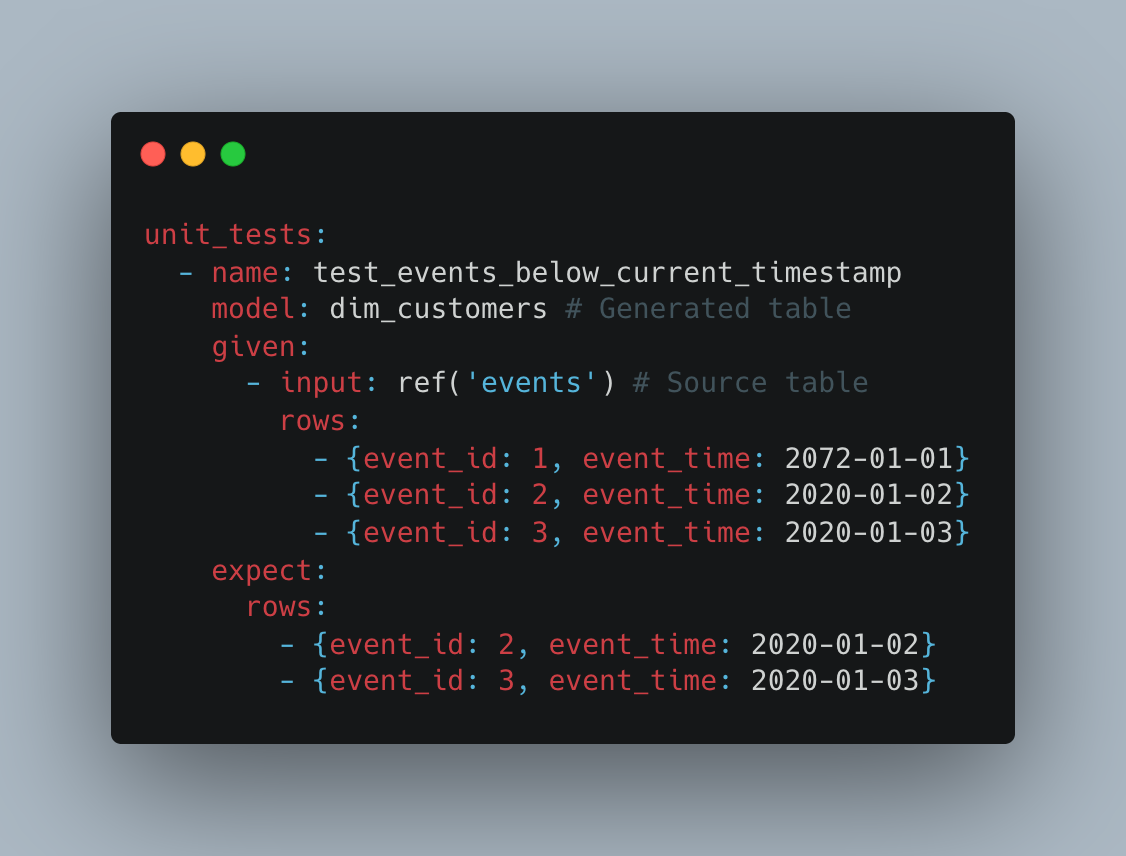
No exemplo acima, estamos criando a tabela dim_customers. Criamos mocks das linhas de input de determinada tabela necessária na lógica SQL (no caso a tabela events) e o output esperado da tabela dim_customers.
WAP - Write, Audit and Publish
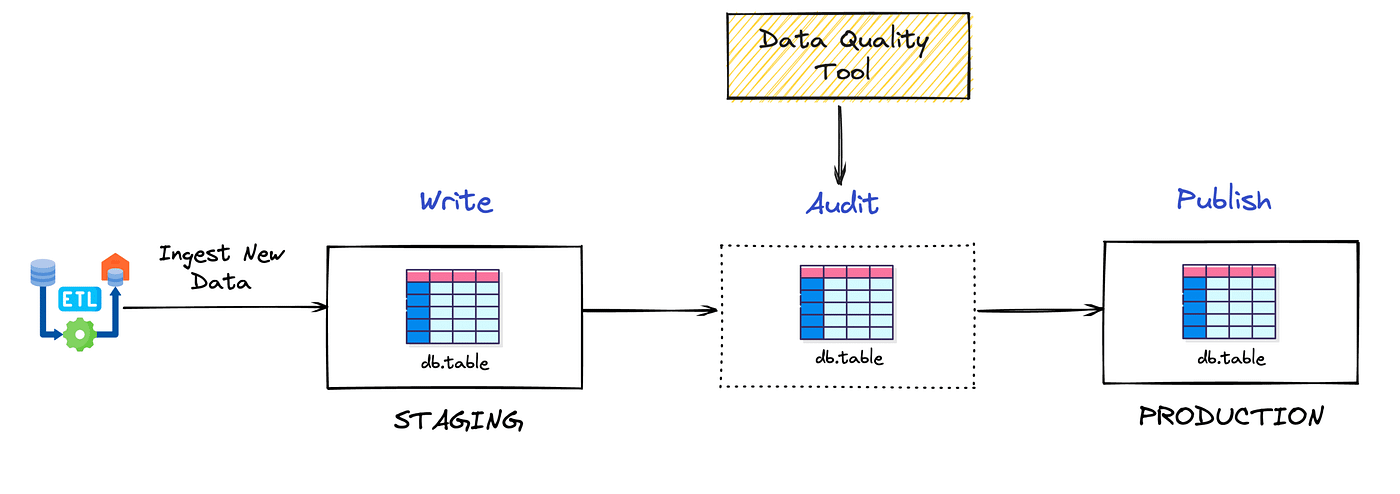
O que é Write, Audit and Publish?
WAP é um padrão arquitetural de dados que introduz duas ramificações de tabelas: staging e production.
- Production: Tabelas de produção que alimentam dashboards, aplicações e clientes finais
- Staging: Tabelas com alterações pendentes que precisam ser validadas antes de serem promovidas para produção
Fluxo: Dados são escritos em staging → passam por todos os checks de qualidade → após validação, são promovidos para production.
Por que WAP é importante?
Além dos testes de coluna, linha, table e comparative, WAP permite testes de regressão entre estados, comparando versões staging vs production da mesma tabela.
Exemplo prático de proteção:
Imagine que você tem uma tabela customers com 50.000 linhas em produção. Um data engineer modifica a lógica SQL acidentalmente introduzindo um filtro restritivo, resultando em apenas 30.000 linhas na versão staging.
- Sem WAP: Os testes de coluna, linha e table continuam passando (pois validam apenas a estrutura e regras internas), e os dados incorretos vão para produção
- Com WAP: Um teste comparativo detecta que houve queda de 40% no número de linhas entre production e staging, bloqueando o deploy e alertando sobre a anomalia antes que afete usuários finais
Este padrão adiciona uma camada crítica de validação que captura regressões e mudanças inesperadas de volumetria que passariam despercebidas em testes isolados.
Exemplo de teste SQL comparando staging vs production
-- Teste: Detectar variação anormal no número de linhas entre production e staging-- Falha se a diferença for maior que 15%
WITH prod_count AS ( SELECT COUNT(*) as total_rows FROM production.customers),staging_count AS ( SELECT COUNT(*) as total_rows FROM staging.customers),comparison AS ( SELECT prod_count.total_rows as prod_rows, staging_count.total_rows as staging_rows, ABS(staging_count.total_rows - prod_count.total_rows) as row_difference, ROUND( 100.0 * ABS(staging_count.total_rows - prod_count.total_rows) / NULLIF(prod_count.total_rows, 0), 2 ) as percentage_change FROM prod_count CROSS JOIN staging_count)SELECT prod_rows, staging_rows, row_difference, percentage_change, CASE WHEN percentage_change > 15 THEN 'FAIL: Variação excede threshold de 15%' ELSE 'PASS' END as test_resultFROM comparisonWHERE percentage_change > 15; -- Query retorna linhas apenas se o teste falharOutros testes comparativos úteis em WAP:
- Validação de valores agregados críticos: Comparar totais (ex: soma de receita, contagem de pedidos ativos)
- Verificação de chaves: Garantir que todas as chaves presentes em production existem em staging
- Detecção de valores nulos novos: Alertar se colunas que não tinham nulos em production passaram a ter em staging
Onde aplicar testes?
Testes nunca são demais, mas não podemos esquecer que consomem recursos: CPU, memória e tempo. Existem estratégias para lidar com isso, como partições e testes heurísticos, que não abordarei aqui.
Agora, se um pipeline é simples, não acho que ter todos os testes que apresentei seja uma opção, talvez seja overengineering.
Acho que os testes mais importantes que devem estar em qualquer lugar são: nulidade, unicidade, referência e valores aceitáveis.
Dashboard de qualidade e log tables
Aqui temos dois conceitos importantes.
Log tables
São tabelas com o objetivo de criar logs sobre seu ETL. Por exemplo: se você tem uma tabela de produtos que deveriam ter número serial, pode criar uma tabela log_product_without_serial_number que mostrará os produtos sem número serial. Você pode simplesmente executar SELECT * FROM log_product_without_serial_number sem precisar acessar seu ETL. Ou talvez você precise de uma tabela log_customer_count que mostre o número de customers em cada tabela que contenha customer_id, permitindo identificar se alguma tabela tem menos customers que o esperado (sim, um comparative test, mas como uma tabela).
Dashboard de qualidade de dados
Com todas as suas log tables, você pode criar um BI centralizado onde visualiza todos os problemas do seu ETL em um único lugar, sem precisar fazer queries. Além disso, pessoas não técnicas podem visualizar e compreender. Por exemplo, se você tem um gráfico indicando que 10% dos produtos estão sem número serial, o responsável por catalogar pode ver quais faltam.
Resumo
Vimos testes de tabela, de coluna, de linha, comparativos, log tables, como testar tabelas entre staging e production e testes unitários.
Esses testes são para pipelines em batch (não em streaming) e para baixa/média volumetria. Claro que tudo isso funciona para Big Data, mas precisaríamos de estratégias de otimização.
Fiquem bem.